Optimising a Noisy Objective Function
I am busy with a project where I need to calibrate the Heston Model to some Asian options data. The model has been implemented as a function which executes a Monte Carlo (MC) simulation. As a result, the objective function is rather noisy. A number of algorithms exist for this sort of problem, and here I simply give a brief overview of some of them.
The Objective Function (with constraint)
For illustrative purposes, I will consider a simple objective function:
\[ f(x, y, z) = x^2 + y^2 + (z - \pi)^2 \]
where solutions will be confined to the first octant (so that x, y and z are all greater than or equal to 0) and subject to the constraint that the product of x and y is greater than or equal to 1. It is clear that the optimum should occur when both x and y are 1 and z equates to pi. However, to make things more interesting, I will evaluate pi using a simple MC method. The objective function is implemented as
obj.func <- function(x) {
if (x[1] * x[2] < 1) {
return(Inf)
}
#
# Generate Monte Carlo estimate of pi
#
r <- sqrt(runif(N, -1, 1)**2 + runif(N, -1, 1)**2)
#
pi.estimate = sum(r <= 1) / N * 4
#
# Objective function
#
return(x[1]**2 + x[2]**2 + (x[3] - pi.estimate)**2)
}Here the constraint on x and y is enforced at the beginning: if the constraint is violated then the objective function returns a value of positive infinity. This has two consequences:
- optimisation procedures will naturally reject these values and
- the discontinuity will break any method which relies on derivatives.
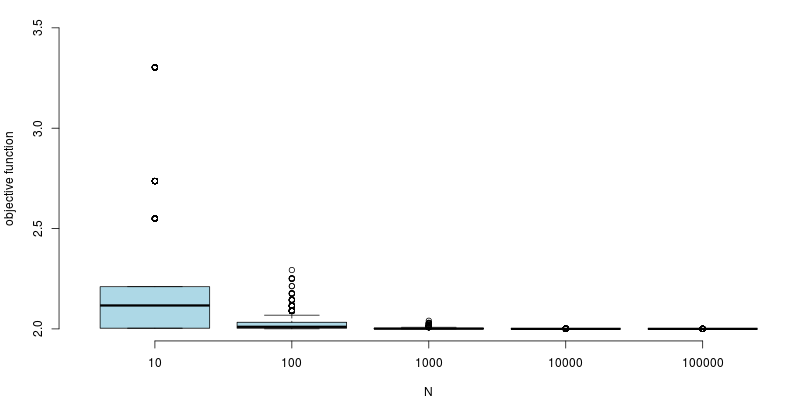
The global parameter N determines the number of iterations in the MC calculation. Obviously, increasing N results in a less noisy estimate of pi. The effect of N can be seen in the boxplot below, where the objective function was repeatedly evaluated with input parameters x = y = 1 and z = pi. For N = 10, 100 or 1000 there is a significant degree of variability between samples. However, with N = 10000 or larger the values are quite stable. We will use N = 10000 since it will result in a relatively good value for pi but still capture some variability.
Differential Evolution
The obvious choice for optimisation is Differential Evolution (DE), which is a member of the class of probabilistic metaheuristics. It works by using a population of candidate solutions, from which new candidates are generated on every iteration. Only the fittest candidates are retained, so that the population gradually migrates towards the optimum. DE does not make any assumptions about the form of the function being optimised. It is thus applicable to scenarios in which the objective function is noisy, stochastic or not differentiable. DE does not guarantee that it will reach the global optimum, but given enough time it should get pretty close!
library(DEoptim)
N = 10000
set.seed(1)
R0 = DEoptim(obj.func, lower = c(0, 0, 2), upper = c(5, 5, 5),
control = DEoptim.control(trace = 10))Iteration: 10 bestvalit: 2.372692 bestmemit: 1.195276 0.907181 2.801708
Iteration: 20 bestvalit: 2.051346 bestmemit: 1.088766 0.928871 3.070025
Iteration: 30 bestvalit: 2.016073 bestmemit: 1.029323 0.977372 3.174193
Iteration: 40 bestvalit: 2.002023 bestmemit: 0.986060 1.014691 3.133731
Iteration: 50 bestvalit: 2.000972 bestmemit: 1.008089 0.992328 3.132118
Iteration: 60 bestvalit: 2.000405 bestmemit: 1.004419 0.995674 3.148528
Iteration: 70 bestvalit: 2.000228 bestmemit: 1.004390 0.995674 3.148528
Iteration: 80 bestvalit: 2.000050 bestmemit: 1.003222 0.996790 3.149576
Iteration: 90 bestvalit: 2.000031 bestmemit: 0.999326 1.000688 3.142246
Iteration: 100 bestvalit: 2.000031 bestmemit: 0.999326 1.000688 3.142246
Iteration: 110 bestvalit: 2.000031 bestmemit: 0.999326 1.000688 3.142246
Iteration: 120 bestvalit: 2.000024 bestmemit: 0.999858 1.000153 3.140956
Iteration: 130 bestvalit: 2.000007 bestmemit: 0.999198 1.000804 3.134417
Iteration: 140 bestvalit: 2.000006 bestmemit: 1.000022 0.999979 3.143176
Iteration: 150 bestvalit: 2.000006 bestmemit: 1.000022 0.999979 3.143176
Iteration: 160 bestvalit: 2.000006 bestmemit: 1.000022 0.999979 3.143176
Iteration: 170 bestvalit: 2.000003 bestmemit: 0.999771 1.000231 3.141439
Iteration: 180 bestvalit: 2.000003 bestmemit: 0.999771 1.000231 3.141439
Iteration: 190 bestvalit: 2.000003 bestmemit: 0.999771 1.000231 3.141439
Iteration: 200 bestvalit: 2.000003 bestmemit: 0.999771 1.000231 3.141439summary(R0)***** summary of DEoptim object *****
best member : 0.99977 1.00023 3.14144
best value : 2
after : 200 generations
fn evaluated : 402 times
*************************************Here the algorithm stopped when it reached the maximum number of iterations. The value obtained for pi is rather respectable, as are the final values for x and y. During the earlier iterations the best fit parameters change fairly rapidly, but towards the end they remain rather static. These results were obtained with the default strategy. Next we will try an alternative strategy:
R1 = DEoptim(obj.func, lower = c(0, 0, 2), upper = c(5, 5, 5),
control = DEoptim.control(trace = 10, strategy = 6))Iteration: 10 bestvalit: 2.407872 bestmemit: 1.107492 0.998561 2.747204
Iteration: 20 bestvalit: 2.078277 bestmemit: 1.107492 0.921314 3.119565
Iteration: 30 bestvalit: 2.060467 bestmemit: 1.052988 0.961616 3.337854
Iteration: 40 bestvalit: 2.013840 bestmemit: 1.049556 0.954623 3.179889
Iteration: 50 bestvalit: 2.001059 bestmemit: 1.012620 0.987738 3.124193
Iteration: 60 bestvalit: 2.001059 bestmemit: 1.012620 0.987738 3.124193
Iteration: 70 bestvalit: 2.001059 bestmemit: 1.012620 0.987738 3.124193
Iteration: 80 bestvalit: 2.001059 bestmemit: 1.012620 0.987738 3.124193
Iteration: 90 bestvalit: 2.000395 bestmemit: 0.997861 1.002304 3.133331
Iteration: 100 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699
Iteration: 110 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699
Iteration: 120 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699
Iteration: 130 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699
Iteration: 140 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699
Iteration: 150 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699
Iteration: 160 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699
Iteration: 170 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699
Iteration: 180 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699
Iteration: 190 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699
Iteration: 200 bestvalit: 2.000345 bestmemit: 0.997861 1.002304 3.148699summary(R1)***** summary of DEoptim object *****
best member : 0.99786 1.0023 3.1487
best value : 2.00034
after : 200 generations
fn evaluated : 402 times
*************************************The final estimate of pi is not as good, but this might be due either to the change in strategy or the random nature of DE. The algorithm again terminates when it reaches the maximum number of iterations. Let’s see what happens if we increase the allowed number of iterations.
R2 = DEoptim(obj.func, lower = c(0, 0, 2), upper = c(5, 5, 5),
control = DEoptim.control(trace = 500, strategy = 6, itermax = 10000))Iteration: 500 bestvalit: 2.000033 bestmemit: 0.999426 1.000589 3.158359
Iteration: 1000 bestvalit: 2.000004 bestmemit: 0.999395 1.000606 3.128536
Iteration: 1500 bestvalit: 2.000001 bestmemit: 0.999848 1.000153 3.114439
Iteration: 2000 bestvalit: 2.000001 bestmemit: 1.000332 0.999669 3.151905
Iteration: 2500 bestvalit: 2.000001 bestmemit: 1.000046 0.999954 3.160268
Iteration: 3000 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.152588
Iteration: 3500 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.152588
Iteration: 4000 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.152588
Iteration: 4500 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.152588
Iteration: 5000 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.152588
Iteration: 5500 bestvalit: 2.000000 bestmemit: 0.999982 1.000018 3.131997
Iteration: 6000 bestvalit: 2.000000 bestmemit: 0.999982 1.000018 3.131997
Iteration: 6500 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.117206
Iteration: 7000 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.117206
Iteration: 7500 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.117206
Iteration: 8000 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.117206
Iteration: 8500 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.117206
Iteration: 9000 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.117206
Iteration: 9500 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.117206
Iteration: 10000 bestvalit: 2.000000 bestmemit: 1.000077 0.999923 3.117206summary(R2)***** summary of DEoptim object *****
best member : 1.00008 0.99992 3.11721
best value : 2
after : 10000 generations
fn evaluated : 20002 times
*************************************Now that is interesting: it seems that by doing more iterations, the final estimate for pi actually gets worse! Not what one would immediately expect… and certainly not the kind of behaviour that one would anticipate from a deterministic objective function. However, this is simply the nature of the beast when optimising in the presence of noise: inevitably you will find sets of parameters which, when combined with noise, will produce progressively lower values for the objective function.
The algorithm still has not converged, but terminated when it reached the maximum number of iterations. To impose a convergence criterion we need to set both the reltol and steptol parameters. The algorithm will converge when the output from the objective function does not change by the specified relative tolerance. This criterion is only applied after steptol number of iterations.
R3 = DEoptim(obj.func, lower = c(0, 0, 2), upper = c(5, 5, 5),
control = DEoptim.control(trace = 10, strategy = 6, itermax = 10000,
steptol = 50, reltol = 1e-10))Iteration: 10 bestvalit: 2.579809 bestmemit: 1.244925 0.900639 3.611781
Iteration: 20 bestvalit: 2.069207 bestmemit: 0.912990 1.111599 3.132970
Iteration: 30 bestvalit: 2.046516 bestmemit: 0.904489 1.108332 3.132970
Iteration: 40 bestvalit: 2.035372 bestmemit: 0.954582 1.059127 3.220126
Iteration: 50 bestvalit: 2.011692 bestmemit: 0.954582 1.049029 3.160340
Iteration: 60 bestvalit: 2.007079 bestmemit: 0.965291 1.036198 3.177824
Iteration: 70 bestvalit: 2.005636 bestmemit: 0.965291 1.036198 3.152725
Iteration: 80 bestvalit: 2.004136 bestmemit: 0.998213 1.003801 3.178253
Iteration: 90 bestvalit: 2.001666 bestmemit: 1.015449 0.984933 3.173284
Iteration: 100 bestvalit: 2.001666 bestmemit: 1.015449 0.984933 3.173284
Iteration: 110 bestvalit: 2.001280 bestmemit: 1.003218 0.997364 3.151892
Iteration: 120 bestvalit: 2.001240 bestmemit: 1.015449 0.984933 3.137954
Iteration: 130 bestvalit: 2.001240 bestmemit: 1.015449 0.984933 3.137954
Iteration: 140 bestvalit: 2.000886 bestmemit: 0.986283 1.013963 3.126322
Iteration: 150 bestvalit: 2.000553 bestmemit: 0.998016 1.002250 3.127560
Iteration: 160 bestvalit: 2.000328 bestmemit: 0.992210 1.007891 3.140559
Iteration: 170 bestvalit: 2.000328 bestmemit: 0.992210 1.007891 3.140559
Iteration: 180 bestvalit: 2.000328 bestmemit: 0.992210 1.007891 3.140559
Iteration: 190 bestvalit: 2.000328 bestmemit: 0.992210 1.007891 3.140559
Iteration: 200 bestvalit: 2.000328 bestmemit: 0.992210 1.007891 3.140559
Iteration: 210 bestvalit: 2.000251 bestmemit: 0.996022 1.004076 3.137558
Iteration: 220 bestvalit: 2.000251 bestmemit: 0.996022 1.004076 3.137558
Iteration: 230 bestvalit: 2.000251 bestmemit: 0.996022 1.004076 3.137558
Iteration: 240 bestvalit: 2.000248 bestmemit: 0.998964 1.001143 3.145631
Iteration: 250 bestvalit: 2.000195 bestmemit: 0.997348 1.002713 3.156045
Iteration: 260 bestvalit: 2.000156 bestmemit: 0.997348 1.002713 3.149641
Iteration: 270 bestvalit: 2.000156 bestmemit: 0.997348 1.002713 3.149641
Iteration: 280 bestvalit: 2.000156 bestmemit: 0.997348 1.002713 3.149641
Iteration: 290 bestvalit: 2.000085 bestmemit: 0.995861 1.004164 3.125551
Iteration: 300 bestvalit: 2.000085 bestmemit: 0.995861 1.004164 3.125551
Iteration: 310 bestvalit: 2.000085 bestmemit: 0.995861 1.004164 3.125551
Iteration: 320 bestvalit: 2.000085 bestmemit: 0.995861 1.004164 3.125551
Iteration: 330 bestvalit: 2.000085 bestmemit: 0.995861 1.004164 3.125551summary(R3)***** summary of DEoptim object *****
best member : 0.99586 1.00416 3.12555
best value : 2.00009
after : 335 generations
fn evaluated : 672 times
*************************************Simulated Annealing
Simulated Annealing (SA) is an alternative optimisation technique, which is also a probabilistic metaheuristic. SA gradually converges on the global optimum by moving probabilistically between states, where the distance between states slowly declines as the algorithm progresses. In contrast to DE, which considers a population of candidate solutions, SA only evolves a single state. SA is implemented in R as an option in the optim() function.
R4 = optim(c(2, 2, 4), obj.func, method = "SANN", control = list(maxit = 1000000, reltol = 1e-6))
R4$par
[1] 0.9983972 1.0016106 3.1274175
$value
[1] 2.000075
$counts
function gradient
1000000 NA
$convergence
[1] 0
$message
NULLBy default optim() should stop after 10000 iterations, however, I pushed this up by a factor of 100. Despite the large number of iterations, the final set of parameters attained is not particularly good. This, again, is due to the noisy objective function. Every time that the objective function is called it uses a new set of random numbers, so that the objective surface is never fixed. Even calling it with the same set of parameters results in a different outcome! The effects of this are more pronounced for SA (as opposed to DE) due to the fact that it only tracks a single state.
Particle Swarm Optimisation
Particle Swarm Optimisation is quite similar to DE in the sense that it uses a population of particles which move around the optimisation domain. Again this is a metaheuristic.
R5 = psoptim(rep(NA, 3), obj.func, lower = c(0, 0, 2), upper = c(5, 5, 5),
control = list(abstol = 2 + 1e-3))
R5$par
[1] 0.9896952 1.0104738 3.1440227
$value
[1] 2.000971
$counts
function iteration restarts
1651 127 0
$convergence
[1] 0
$message
[1] "Converged"The Objective Function (without constraint)
Other methods will work with a noisy objective function. However, they do not function with the internally imposed constraint. To see how these work we need to remove the constraint code. We will simplify the constraint by asserting that both x and y are greater than or equal to 1 (but this is done in the optimiser and not in the objective function). This is a slightly different problem but has the same solution.
obj.func <- function(x) {
r <- sqrt(runif(N, -1, 1)**2 + runif(N, -1, 1)**2)
#
pi.estimate = sum(r <= 1) / N * 4
#
return(x[1]**2 + x[2]**2 + (x[3] - pi.estimate)**2)
}Derivative-Free Nelder-Mead
This method is described in Kelley, C. T. (1999). Iterative Methods for Optimization. SIAM.
library(dfoptim)
R6 = nmkb(c(2, 2, 4), obj.func, lower = c(1, 1, 2), upper = c(5, 5, 5))> R6$par
[1] 1.000021 1.000022 3.118085
> R6$feval
[1] 153
> R6$message
[1] "Successful convergence"This converges on a reasonable solution without using too many function evaluations. It is relatively quick. The final set of parameters could probably be improved by tweaking some of the optional arguments to nmkb(). The result might be used as an initial solution for a more intensive optimisation.
Multi-objective Particle Swarm Optimization with Crowding Distance
This method has the capability to simultaneously optimise multiple objective functions. Although this is not applied here, it is certainly a very useful feature!
library(mopsocd)
R7 = mopsocd(obj.func, varcnt = 3, fncnt = 1, lowerbound = c(1, 1, 2), upperbound = c(5, 5, 5),
opt = 0)
R7$paramvalues[1] 1.00000 1.00000 3.14839mopsocd() actually provides the option of applying a constraint as a separate function. I could not, however, get this to work effectively with this example.
A Cautionary Note
Because these optimisation functions used here rely on a stream of random numbers, you should not consider resetting the random number seed within the objective function. Why would you do this? Well, it is one way to ensure that you get a reproducible value out of the objective function for a particular set of parameters. This might be important for debugging purposes, but it will completely break the optimisation.
Acknowledgements
Thank you to the helpful folk at Stack Overflow who gave some excellent suggestions which contributed to the content of this article.