Correlations with Uncertainty: Bootstrap Solution
A week or so ago a colleague of mine asked if I knew how to calculate correlations for data with uncertainties. Now, if we are going to be honest, then all data should have some level of experimental or measurement error. However, I suspect that in the majority of cases these uncertainties are ignored when considering correlations. To what degree are uncertainties important? A moment’s thought would suggest that if the uncertainties are large enough then they should have a rather significant effect on correlation, or more properly, the uncertainty measure associated with the correlation. What is the best (or at least correct) way to proceed? Somewhat surprisingly a quick Google search did not turn up anything too helpful.
Let’s make this problem a little more concrete. My colleague’s data are plotted below. The independent variable is assumed to be well known but the dependent variable has measurement error. For each value of the independent variable multiple measurements of the dependent variable have been made. The average (mu) and standard deviation (sigma) of these measurements have then been recorded. A systematic trend appears in the measurement uncertainties, with larger error bars generally occurring for larger values of the independent variable (although there are some obvious exceptions!).
head(original)mu.x sigma.x mu.y sigma.y
1 93.7 0 56.80 83.5
2 48.5 0 15.20 24.0
3 85.0 0 79.10 150.0
4 38.3 0 9.17 11.2
5 97.3 0 43.10 77.0
6 44.2 0 36.70 76.2
```r
library(ggplot2)
ggplot(original, aes(x=mu.x, y=mu.y)) +
geom_errorbar(aes(ymin=mu.y-sigma.y, ymax=mu.y+sigma.y),
colour="black", width = .05, alpha = 0.5) +
geom_point(size=3, shape=21, fill="lightgreen", alpha = 0.75) +
xlab("x") + ylab("y") +
theme_bw() +
scale_x_log10()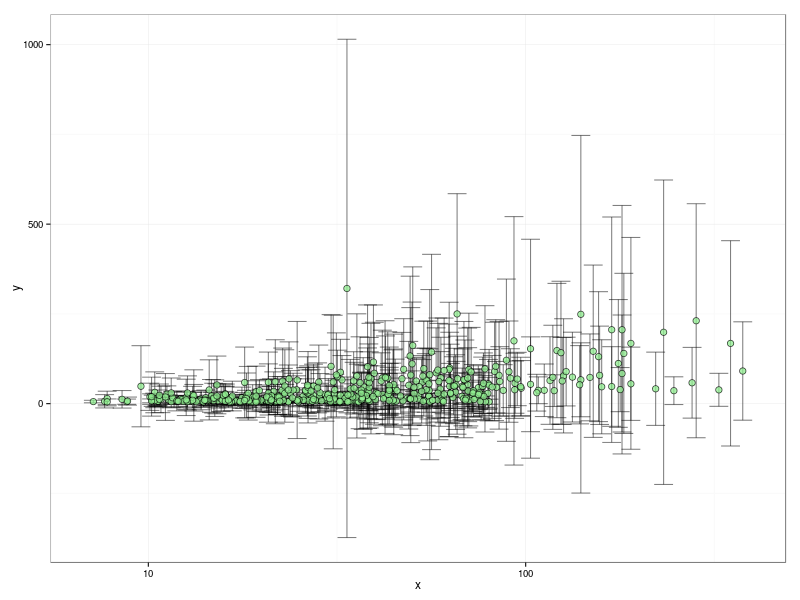
Now since I can’t publish those data, we will need to construct a synthetic data set in order to explore this issue.
set.seed(1)
N <- 100
synthetic <- data.frame(mu.x = runif(N), sigma.x = 0)
synthetic <- transform(synthetic, mu.y = mu.x + rnorm(N), sigma.y = runif(N))
head(synthetic)mu.x sigma.x mu.y sigma.y
1 0.2655087 0 0.6636145 0.67371223
2 0.3721239 0 -0.2399025 0.09485786
3 0.5728534 0 0.9139731 0.49259612
4 0.9082078 0 -0.2211553 0.46155184
5 0.2016819 0 1.6347056 0.37521653
6 0.8983897 0 2.8787896 0.99109922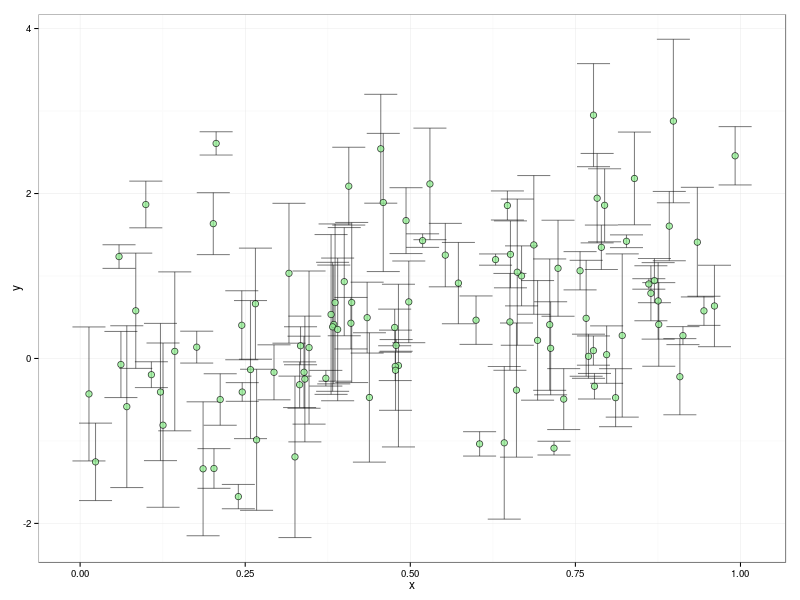
The direct approach to calculating the correlation would be to just use the average values for each measurement.
attach(synthetic)
cor.test(mu.x, mu.y) Pearson's product-moment correlation
data: mu.x and mu.y
t = 3.7129, df = 98, p-value = 0.0003405
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.1662162 0.5122542
sample estimates:
cor
0.3511694detach(synthetic)This looks eminently reasonable: a correlation coefficient of 0.351 (significant at the 1% level) and a 95% confidence interval extending from 0.166 to 0.512.
We can assess the influence of the uncertainties by performing a bootstrap calculation. Let’s keep things simple to start with, using only the mean values.
cor.mu <- function(df, n) {
df = df[n,]
x <- df$mu.x
y <- df$mu.y
return(cor(x, y))
}
(boot.cor.mu = boot(synthetic, cor.mu, R = 100000))ORDINARY NONPARAMETRIC BOOTSTRAP
Call:
boot(data = synthetic, statistic = cor.mu, R = 1e+05)
Bootstrap Statistics :
original bias std. error
t1* 0.3511694 -0.001089294 0.09143083boot.ci(boot.cor.mu, type = c("norm", "basic", "perc"))BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 100000 bootstrap replicates
CALL :
boot.ci(boot.out = boot.cor.mu, type = c("norm", "basic", "perc"))
Intervals :
Level Normal Basic Percentile
95% ( 0.1731, 0.5315 ) ( 0.1827, 0.5394 ) ( 0.1630, 0.5196 )
Calculations and Intervals on Original ScaleNote that we are still only using the measurement means! The new bootstrap values for the correlation coefficient and its confidence interval are in good agreement with the direct results above. But that is no surprise because nothing has really changed. Yet.
Next we will adapt the bootstrap function so that it generates data by random sampling from normal distributions with means and standard deviations extracted from the data.
cor.mu.sigma <- function(df, n) {
df = df[n,]
x <- rnorm(nrow(df), mean = df$mu.x, sd = df$sigma.x)
y <- rnorm(nrow(df), mean = df$mu.y, sd = df$sigma.y)
return(cor(x, y))
}
(boot.cor.mu.sigma = boot(synthetic, cor.mu.sigma, R = 100000))ORDINARY NONPARAMETRIC BOOTSTRAP
Call:
boot(data = synthetic, statistic = cor.mu.sigma, R = 1e+05)
Bootstrap Statistics :
original bias std. error
t1* 0.2699615 0.03208843 0.09144613The bootstrap estimate of the correlation, 0.270, is quite different to the direct and simple bootstrap results. However, we now also have access to the bootstrap confidence intervals which take into account the uncertainty in the observations.
boot.ci(boot.cor.mu.sigma, type = c("norm", "basic", "perc"))BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 100000 bootstrap replicates
CALL :
boot.ci(boot.out = boot.cor.mu.sigma, type = c("norm", "basic",
"perc"))
Intervals :
Level Normal Basic Percentile
95% ( 0.0586, 0.4171 ) ( 0.0672, 0.4232 ) ( 0.1167, 0.4727 )
Calculations and Intervals on Original ScaleThe 95% confidence interval for the correlation, taking into account uncertainties in the measurements, extends from 0.059 to 0.417. The correlation is still significant at the 5% level, but barely so!
Returning now to the original data and applying the same analysis. First we go the direct route.
attach(original)
cor.test(mu.x, mu.y) Pearson's product-moment correlation
data: mu.x and mu.y
t = 13.5402, df = 445, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.4710180 0.6027208
sample estimates:
cor
0.5401686 detach(original)Next we look at the bootstrap approach.
(boot.cor.mu.sigma = boot(original, cor.mu.sigma, R = 100000))ORDINARY NONPARAMETRIC BOOTSTRAP
Call:
boot(data = original, statistic = cor.mu.sigma, R = 1e+05)
Bootstrap Statistics :
WARNING: All values of t1* are NA
There were 50 or more warnings (use warnings() to see the first 50)Hmmmm. That’s no good: it breaks because there is a single record which has missing data for sigma.
original[rowSums(is.na(original)) > 0,]mu.x sigma.x mu.y sigma.y
80 52.2 0 47.6 NaNTo deal with this small hitch we make a change to the bootstrap function to include only complete observations.
cor.mu.sigma <- function(df, n) {
df = df[n,]
x <- rnorm(nrow(df), mean = df$mu.x, sd = df$sigma.x)
y <- rnorm(nrow(df), mean = df$mu.y, sd = df$sigma.y)
return(cor(x, y, use = "complete.obs"))
}
(boot.cor.mu.sigma = boot(original, cor.mu.sigma, R = 100000))ORDINARY NONPARAMETRIC BOOTSTRAP
Call:
boot(data = original, statistic = cor.mu.sigma, R = 1e+05)
Bootstrap Statistics :
original bias std. error
t1* 0.1938031 0.01834959 0.08378789
There were 50 or more warnings (use warnings() to see the first 50)The warnings are generated because rnorm() is still producing NAs. Maybe a better approach would have been to only pass complete observations to boot() using complete.cases(). The bootstrap estimate of the correlation is quite different from what we obtained using the direct method!
boot.ci(boot.cor.mu.sigma, type = c("norm", "basic", "perc"))BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 100000 bootstrap replicates
CALL :
boot.ci(boot.out = boot.cor.mu.sigma, type = c("norm", "basic",
"perc"))
Intervals :
Level Normal Basic Percentile
95% ( 0.0112, 0.3397 ) ( 0.0135, 0.3414 ) ( 0.0462, 0.3741 )
Calculations and Intervals on Original Scaleplot(boot.cor.mu.sigma)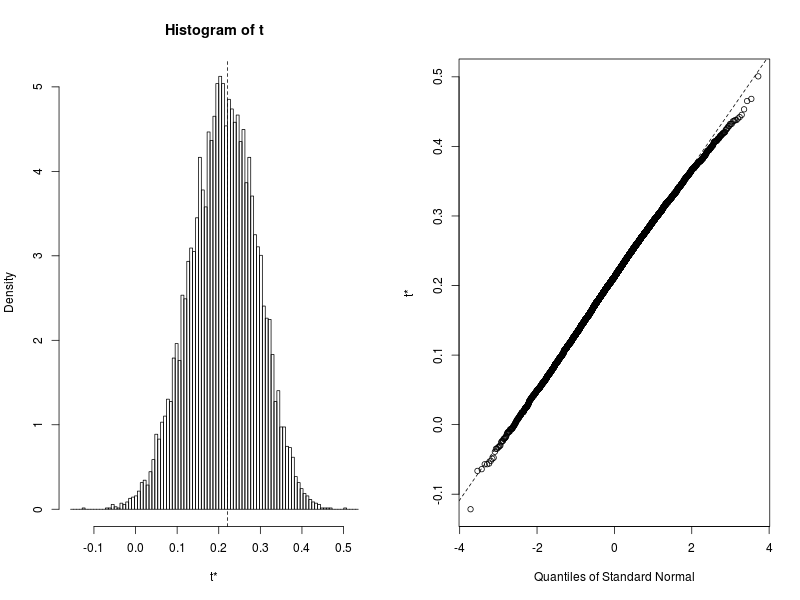
The bootstrap 95% confidence interval for the correlation does not include zero, but it comes rather close! We can still conclude that the correlation is significant, although it might be a mistake to place too much faith in it.
I am not foolish enough to assert that this is the best (or even correct) way for dealing with this situation. But at least to me it seems to be feasible. I would be extremely pleased to receive feedback on problems with this approach and suggestions for how it might be improved.