Top 250 Movies at IMDb
Some years ago I allowed myself to accept a challenge to read the Top 100 Novels of All Time (complete list here). This list was put together by Richard Lacayo and Lev Grossman at Time Magazine.
To start with I could tick off a number of books that I had already read. That left me with around 75 books outstanding. I knuckled down. The Lord of the Rings had been on my reading list for a number of years, so this was my first project. A little unfair for this trilogy to count as just one book… but I consumed it with gusto! One down. Other books followed. They were also great reads. And then I hit a couple of books that were just, well, to put it plainly, heavy going. I am sure that they were great books and my lack of enjoyment was entirely a reflection on me and not the quality of the books. No doubt I learned a lot from reading them. But it was hard work! At this stage it occurred to me that the book list was constructed from a rather specific perspective of what constituted a great book. A perspective which is quite different from my own. I had to admit defeat: my literary tastes will have to mature a bit before I attack this list again!
Then last week I was reading through a back issue of The Linux Journal and came across an article which used shell tools to download and process the IMDb list of Top 250 Movies. This list is constructed from IMDb users’ votes and so represents a fairly democratic and egalitarian perspective. Working through a list of movies seems to me to be a lot easier than a list of books, so this appealed to my inner sloth. And gave me an idea for a quick little R script.
We will use the XML library to retrieve the page from IMDb and parse out the appropriate table.
library(XML)
url <- "https://www.imdb.com/chart/top"
best.movies <- readHTMLTable(url, which = 2, stringsAsFactors = FALSE)
head(best.movies)Rank Rating Title Votes
1 1. 9.2 The Shawshank Redemption (1994) 1,065,332
2 2. 9.2 The Godfather (1972) 746,693
3 3. 9.0 The Godfather: Part II (1974) 484,761
4 4. 8.9 Pulp Fiction (1994) 825,063
5 5. 8.9 The Good, the Bad and the Ugly (1966) 319,222
6 6. 8.9 The Dark Knight (2008) 1,039,499The output reflects the content of the rating table exactly. However, the rank column is redundant since the same information is captured by the row labels. We can remove this column to make the data more concise.
best.movies[, 1] <- NULL
head(best.movies) Rating Title Votes
1 9.2 The Shawshank Redemption (1994) 1,065,332
2 9.2 The Godfather (1972) 746,693
3 9.0 The Godfather: Part II (1974) 484,761
4 8.9 Pulp Fiction (1994) 825,063
5 8.9 The Good, the Bad and the Ugly (1966) 319,222
6 8.9 The Dark Knight (2008) 1,039,499A few remaining issues:
- the years are bundled up with the titles;
- the rating data are strings;
- the votes data are also strings and have embedded commas.
All of these problems are easily fixed though.
pattern = "(.*) \\((.*)\\)$"
best.movies = transform(
best.movies,
Rating = as.numeric(Rating),
Year = as.integer(substr(gsub(pattern, "\\2", Title), 1, 4)),
Title = gsub(pattern, "\\1", Title),
Votes = as.integer(gsub(",", "", Votes))
)
best.movies = best.movies[, c(4, 2, 3, 1)]
head(best.movies) Year Title Votes Rating
1 1994 The Shawshank Redemption 1065332 9.2
2 1972 The Godfather 746693 9.2
3 1974 The Godfather: Part II 484761 9.0
4 1994 Pulp Fiction 825063 8.9
5 1966 The Good, the Bad and the Ugly 319222 8.9
6 2008 The Dark Knight 1039499 8.9I am happy to see that The Good, the Bad and the Ugly rates at number 5. This is one of my favourite movies! Clearly I am not alone.
Finally, to gain a little perspective on the relationship between the release year, votes and rating we can put together a simple bubble plot.
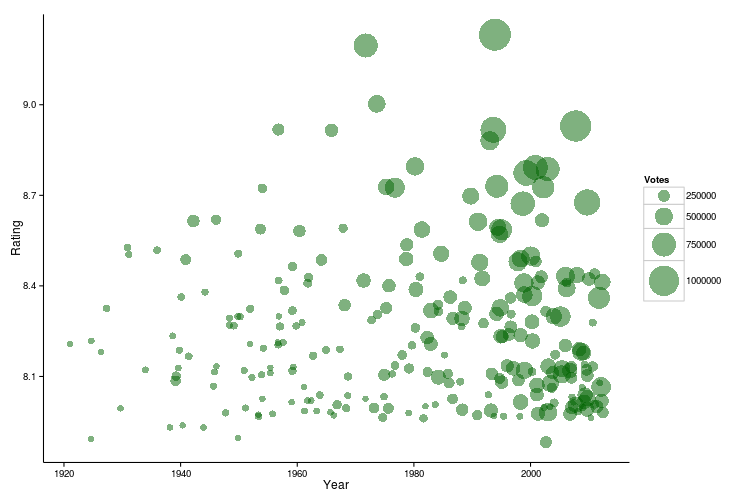
library(ggplot2)
ggplot(best.movies, aes(x = Year, y = Rating)) +
geom_point(aes(size = Votes), alpha = 0.5, position = "jitter", color = "darkgreen") +
scale_size(range = c(3, 15)) +
theme_classic()When I have some more time on my hands I am going to use the IMDb API to grab some additional information on each of these movies and see if anything interesting emerges from the larger data set.