Simulating Intricate Branching Patterns with DLA
Manfred Schroeder’s book Fractals, Chaos, Power Laws: Minutes from an Infinite Paradise is a fruitful source of interesting topics and projects. He gives a thorough description of Diffusion-Limited Aggregation (DLA) as a technique for simulating physical processes which produce intricate branching structures. Examples, as illustrated below, include Lichtenberg Figures, dielectric breakdown, electrodeposition and Hele-Shaw flow.

Diffusion-Limited Aggregation
DLA is conceptually simple. A seed particle is fixed at the origin of the coordinate system. Another particle is introduced at a relatively large distance from the origin, which then proceeds to move on a random walk. Either it will wander off to infinity or it will come into contact with the particle at the origin, to which it sticks irreversibly. Now another particle is introduced and the process repeats itself. As successive particles are added to the system, a portion of them become bound to the growing cluster of particles at the origin.
The objects which evolve from this process are intrinsically random, yet have self-similar structure across a range of scales. Once a protuberance has formed on the cluster, further particles are more likely to adhere to it since they will probably encounter it first, yielding positive feedback.
A Simple Implementation in R
First we need to construct a grid. We will start small: a 20 by 20 grid filled with NA except for four seed locations at the centre.
# Dimensions of grid
W <- 20
grid <- matrix(NA, nrow = W, ncol = W)
grid[W/2 + c(0, 1), W/2 + c(0, 1)] = 0
grid [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17] [,18] [,19] [,20]
[1,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[2,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[3,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[4,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[5,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[6,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[7,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[8,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[9,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[10,] NA NA NA NA NA NA NA NA NA 0 0 NA NA NA NA NA NA NA NA NA
[11,] NA NA NA NA NA NA NA NA NA 0 0 NA NA NA NA NA NA NA NA NA
[12,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[13,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[14,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[15,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[16,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[17,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[18,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[19,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[20,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NAWe need to generate two dimensional random walks. To do this I created a table of possible moves, from which individual steps could be sampled at random. The table presently only caters for the cells immediately above, below, left or right of the current cell. It would be a simple matter to extend the table to allow diagonal moves as well, but these more distant moves would need to be weighted accordingly.
moves <- data.frame(dx = c(0, 0, +1, -1), dy = c(+1, -1, 0, 0))
#
M = nrow(moves)
moves dx dy
1 0 1
2 0 -1
3 1 0
4 -1 0Next a function to transport a particle from its initial location until it either leaves the grid or adheres to the cluster at the origin. Again a possible refinement here would be to allow sticking to next-nearest neighbours as well
diffuse <- function(p) {
count = 0
#
while (TRUE) {
p = p + moves[sample(M, 1),]
#
count = count + 1
#
# Black boundary conditions
#
if (p$x > W | p$y > W | p$x < 1 | p$y < 1) return(NA)
#
# Check if it sticks (to nearest neighbour)
#
if (p$x < W && !is.na(grid[p$x+1, p$y])) break
if (p$x > 1 && !is.na(grid[p$x-1, p$y])) break
if (p$y < W && !is.na(grid[p$x, p$y+1])) break
if (p$y > 1 && !is.na(grid[p$x, p$y-1])) break
}
#
return(c(p, count = count))
}Finally we are ready to apply this procedure to a batch of particles.
library(foreach)
# Number of particles per batch
#
PBATCH <- 5000
#
# Select starting position
#
phi = runif(PBATCH, 0, 2 * pi)
#
x = round((1 + cos(phi)) * W / 2 + 0.5)
y = round((1 + sin(phi)) * W / 2 + 0.5)
#
particles <- data.frame(x, y)
result = foreach(n = 1:PBATCH) %do% diffuse(particles[n,])
lapply(result, function(p) {if (length(p) == 3) grid[p$x, p$y] <<- p$count})The resulting grid shows all of the locations where particles have adhered to the cluster. The number at each location is the diffusion time, which indicates the number of steps required for the particle to move from its initial location to its final resting place. The shape of the cluster is a little boring at present: essentially a circular disk centred on the origin. This is due to the size of the problem and we will need to have a much larger grid to produce more interesting structure.
grid [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14] [,15] [,16] [,17] [,18] [,19] [,20]
[1,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[2,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
[3,] NA NA NA NA NA NA NA NA NA 2 18 NA NA NA NA NA NA NA NA NA
[4,] NA NA NA NA NA NA NA NA 8 6 17 10 NA NA NA NA NA NA NA NA
[5,] NA NA NA NA NA NA NA 6 11 7 54 25 15 NA NA NA NA NA NA NA
[6,] NA NA NA NA NA NA 16 10 11 58 69 18 31 16 NA NA NA NA NA NA
[7,] NA NA NA NA NA 20 19 10 21 24 32 50 24 65 8 NA NA NA NA NA
[8,] NA NA NA NA 18 12 55 26 13 151 86 20 21 26 27 34 NA NA NA NA
[9,] NA NA NA 56 21 43 19 53 43 30 26 37 66 52 30 22 10 NA NA NA
[10,] NA NA 29 9 9 23 70 38 48 0 0 122 26 44 22 10 27 5 NA NA
[11,] NA NA 2 9 10 36 32 38 24 0 0 54 14 21 65 14 30 29 NA NA
[12,] NA NA NA 5 10 16 13 83 52 43 23 42 39 23 66 9 32 NA NA NA
[13,] NA NA NA NA 21 70 28 31 NA 41 61 15 17 29 25 17 NA NA NA NA
[14,] NA NA NA NA NA 8 29 19 7 47 119 37 19 9 10 NA NA NA NA NA
[15,] NA NA NA NA NA NA 15 33 68 26 38 13 33 8 NA NA NA NA NA NA
[16,] NA NA NA NA NA NA NA 10 12 12 15 35 11 NA NA NA NA NA NA NA
[17,] NA NA NA NA NA NA NA NA 20 8 6 5 NA NA NA NA NA NA NA NA
[18,] NA NA NA NA NA NA NA NA NA 18 20 NA NA NA NA NA NA NA NA NA
[19,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA
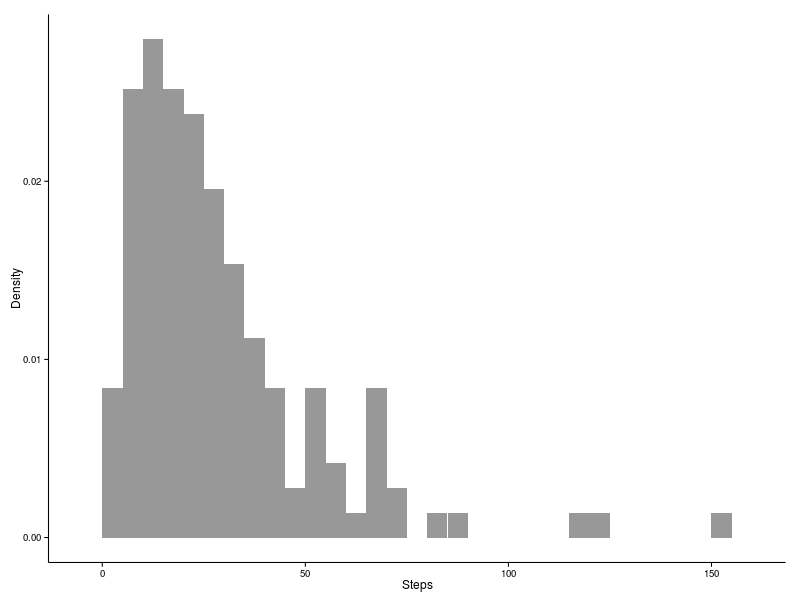
[20,] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NATaking a look at the distribution of diffusion times below we can see that there is a strong peak between 10 and 15. The majority of particles diffuse in less than 40 steps, while the longest diffusion time is 151 steps. The grid above shows that, as one would expect, smaller diffusion times are found close to the surface of the cluster, while longer times are embedded closer to the core.
Scaling it Up
To produce a more interesting cluster we need to scale the grid size up considerably. But this also means that the run time escalates enormously. To make this even remotely tractable, I had to parallelise the algorithm. I did this using the {SNOW} package and ran it on an MPI cluster. The changes to the code are trivial, involving only the creation and initialisation of the cluster and changing %do% to %dopar% in the foreach() loop.
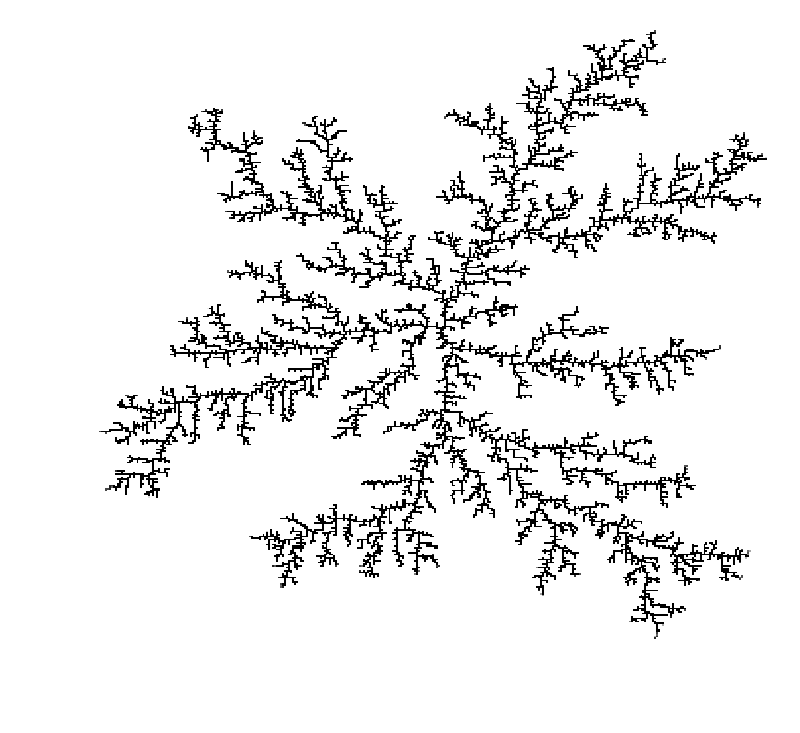
Conclusion
This is nowhere near being an efficient implementation of DLA. But it gets the job done and is illustrative of how the algorithm works. To do production runs one would want to code the algorithm in a low-level language like C or C++ and take advantage of the inherent parallelism of the algorithm.