I am going to be using the party package for one of my projects, so I spent some time today familiarising myself with it. The details of the package are described in Hothorn, T., Hornik, K., & Zeileis, A. (1999). “party: A Laboratory for Recursive Partytioning” which is available from CRAN.
The main workhorse of the package is ctree, so that is where I will be focusing my attention. The online documentation for ctree is, to be honest, like much of the R documentation: somewhat dense. Or maybe it is just me being dense? Anyway, the examples provided do illustrate what ctree can do, but do not give too much in the way of explanation about just what it is doing. I am going to try and unpack those examples in detail.
Ozone
The air quality data set looks like this.
head(airquality)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
The first thing that we will do is remove all of the records with missing ozone data.
airq <- subset(airquality, !is.na(Ozone))
Next we use ctree to construct a model of ozone as a function of all other covariates.
air.ct <- ctree(Ozone ~ ., data = airq, controls = ctree_control(maxsurrogate = 3))
air.ct
Conditional inference tree with 5 terminal nodes
Response: Ozone
Inputs: Solar.R, Wind, Temp, Month, Day
Number of observations: 116
1) Temp <= 82; criterion = 1, statistic = 56.086
2) Wind <= 6.9; criterion = 0.998, statistic = 12.969
3)* weights = 10
2) Wind > 6.9
4) Temp <= 77; criterion = 0.997, statistic = 11.599
5)* weights = 48
4) Temp > 77
6)* weights = 21
1) Temp > 82
7) Wind <= 10.3; criterion = 0.997, statistic = 11.712
8)* weights = 30
7) Wind > 10.3
9)* weights = 7
The textual description of the model gives a lot of detail, but it is a little difficult to get the big picture. A plot helps. This is essentially a decision tree but with extra information in the terminal nodes.
plot(air.ct)
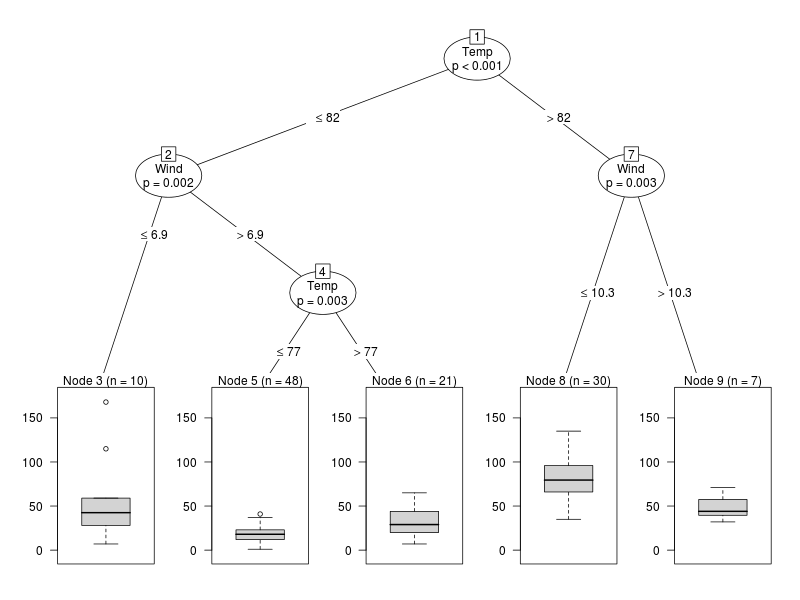
This tells us that the data has been divided up into five classes (in nodes labelled 3, 5, 6, 8 and 9). Let’s consider a measurement with temperature of 70 and wind speed of 12. At the highest level the data is divided into two categories according to temperature: either ≤ 82 or > 82. Our measurement follows the left branch (temperature ≤ 82). The next division is made according to wind speed, giving two categories according to whether the speed is ≤ 6.9 or > 6.9. Our measurement follows the right branch (speed > 6.9). Then we encounter the final division, which once again depends on temperature and has two categories: either ≤ 77 or > 77. Our measurement has temperature ≤ 77, so it gets classified in node 5. Looking at the boxplot for ozone in node 5, this suggests that we would expect the conditions for our measurement to be associated with a relatively low level of ozone.
We can look at the details of individual nodes in the tree, but this does not reveal much more information than was already given in the plot.
nodes(air.ct, 1)
[[1]]
1) Temp <= 82; criterion = 1, statistic = 56.086
2) Wind <= 6.9; criterion = 0.998, statistic = 12.969
3)* weights = 10
2) Wind > 6.9
4) Temp <= 77; criterion = 0.997, statistic = 11.599
5)* weights = 48
4) Temp > 77
6)* weights = 21
1) Temp > 82
7) Wind <= 10.3; criterion = 0.997, statistic = 11.712
8)* weights = 30
7) Wind > 10.3
9)* weights = 7
nodes(air.ct, 2)
[[1]]
2) Wind <= 6.9; criterion = 0.998, statistic = 12.969
3)* weights = 10
2) Wind > 6.9
4) Temp <= 77; criterion = 0.997, statistic = 11.599
5)* weights = 48
4) Temp > 77
6)* weights = 21
What about using this model on new data? First we construct a new data frame.
new.airq new.airq
Solar.R Wind Temp Month Day
1 0 5 70 0 0
2 0 12 70 0 0
3 0 5 80 0 0
4 0 12 80 0 0
5 0 5 90 0 0
6 0 12 90 0 0
Note that since the classification model does not depend on solar radiation, month or day, we do not need to specify meaningful values for them (they will not have any impact on the outcome of the model!). One of the characteristics of party is that it does not include in the model any covariates which appear to be independent of the response variable.
It is very important to ensure that the column classes in the new data are precisely the same as those in the original training data. If you don’t then prediction will fail.
sapply(airq[,-1], class)
Solar.R Wind Temp Month Day
"integer" "numeric" "integer" "integer" "integer"
sapply(new.airq, class)
Solar.R Wind Temp Month Day
"integer" "numeric" "integer" "integer" "integer"
Now we can predict the ozone levels and category node numbers for these new data. The measurement used above to discuss the plot (temperature 70, wind speed 12) appears on row 2 of these new data.
cbind(new.airq, predict(air.ct, newdata = new.airq))
Solar.R Wind Temp Month Day Ozone
1 0 5 70 0 0 55.60000
2 0 12 70 0 0 18.47917
3 0 5 80 0 0 55.60000
4 0 12 80 0 0 31.14286
5 0 5 90 0 0 81.63333
6 0 12 90 0 0 48.71429
predict(air.ct, newdata = new.airq, type = "node")
[1] 3 5 3 6 8 9
Finally we can use the model to generate the category node numbers for the original data and add that as a new column to the data frame.
airq$node = predict(air.ct, type = "node")
head(airq)
Ozone Solar.R Wind Temp Month Day node
1 41 190 7.4 67 5 1 5
2 36 118 8.0 72 5 2 5
3 12 149 12.6 74 5 3 5
4 18 313 11.5 62 5 4 5
6 28 NA 14.9 66 5 6 5
7 23 299 8.6 65 5 7 5
Like many things in R, you could have achieved this result by other means.
where(air.ct)
[1] 5 5 5 5 5 5 5 5 3 5 5 5 5 5 5 5 5 5 5 5 5 5 5 6 3 5 6 9 9 6 5 5 5 5 5 8 8 6 8 9 8 8 8 8 5 6 6
[48] 3 6 8 8 9 3 8 8 6 9 8 8 8 6 3 6 6 8 8 8 8 8 8 9 6 6 5 3 5 6 6 5 5 6 3 8 8 8 8 8 8 8 8 8 8 9 6
[95] 6 5 5 6 5 3 5 5 3 5 5 5 6 5 5 6 5 5 3 5 5 5
Irises
The iris data set gives data on the dimensions of sepals and petals measured on 50 samples of three different species of iris (Setosa, Versicolor and Virginica).
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
We will construct a model of iris species as a function of the other covariates.
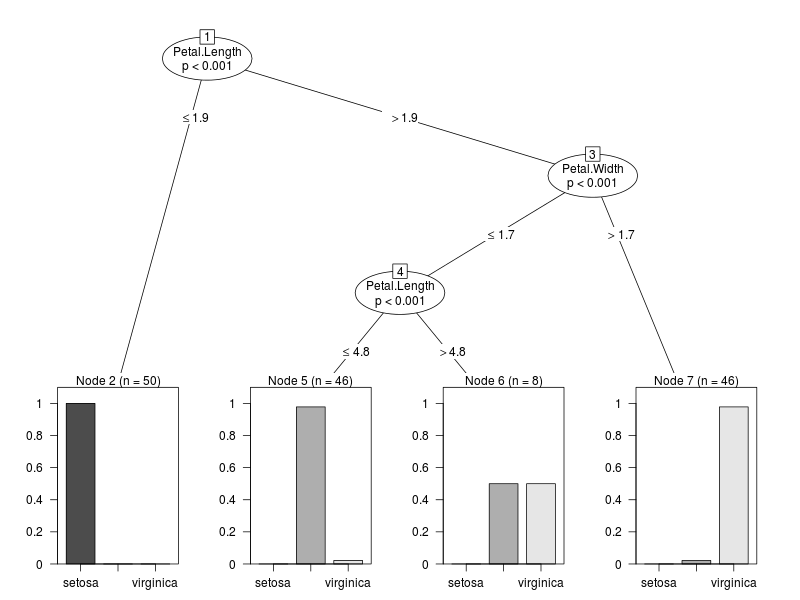
iris.ct <- ctree(Species ~ .,data = iris)
plot(iris.ct)
The structure of the tree is essentially the same. Only the representation of the nodes differs because, whereas ozone was a continuous numerical variable, iris species is a categorical variable. The nodes are thus represented as bar plots. Node 2 is predominantly Setosa, node 5 is mostly Versicolor and node 7 is almost all Virginica. Node 6 is half Versicolor and half Virginica and corresponds to a category with long, narrow petals. It is interesting to note that the model depends only on the dimensions of the petals and not on those of the sepals.
We can assess the quality of the model by constructing a confusion matrix. This shows that the model performs perfectly for Setosa irises. For Versicolor it also performs very well, only classifying one sample incorrectly as a Virginica. For Virginica it fails to correctly classify 5 samples. The model seems to perform well overall, however, this is based on the training data, so it is not really an objective assessment.
table(iris$Species, predict(iris.ct), dnn = c("Actual species", "Predicted species"))
Predicted species
Actual species setosa versicolor virginica
setosa 50 0 0
versicolor 0 49 1
virginica 0 5 45
Finally, we can use the model to predict the species for new data.
new.iris head(new.iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 0 0 1 1
2 0 0 4 2
3 0 0 5 1
4 0 0 4 1
5 0 0 5 2
predict(iris.ct, newdata = new.iris)
[1] setosa virginica versicolor versicolor virginica
Levels: setosa versicolor virginica
predict(iris.ct, newdata = new.iris, type = "node")
[1] 2 7 6 5 7
Mammography
The mammography data details a study on the benefits of mammography.
head(mammoexp)
ME SYMPT PB HIST BSE DECT
1 Never Disagree 7 No Yes Somewhat likely
2 Never Agree 11 No Yes Very likely
3 Never Disagree 8 Yes Yes Very likely
4 Within a Year Disagree 11 No Yes Very likely
5 Over a Year Strongly Disagree 7 No Yes Very likely
6 Never Disagree 7 No Yes Very likely
We will model the first field which indicates when last the sample had a mammogram.
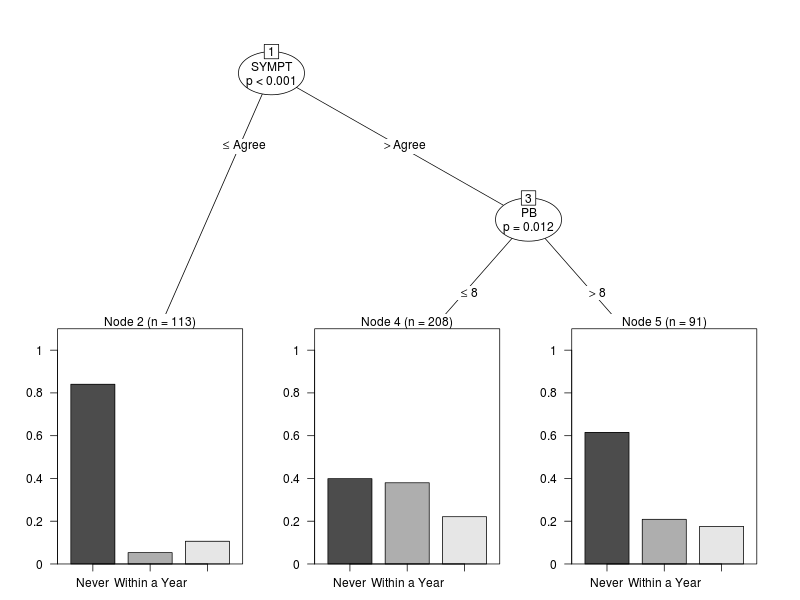
plot(mammo.ct)
Again the nodes in the model appear in the form of a bar plot since they represent a categorical variable. The model classifies the data according to SYMPT and PB, where the former is an ordinal variable which reflects agreement with the statement “You do not need a mammogram unless you develop symptoms” and the latter is an indicator of the perceived benefit of mammography.
German Breast Cancer Study Group
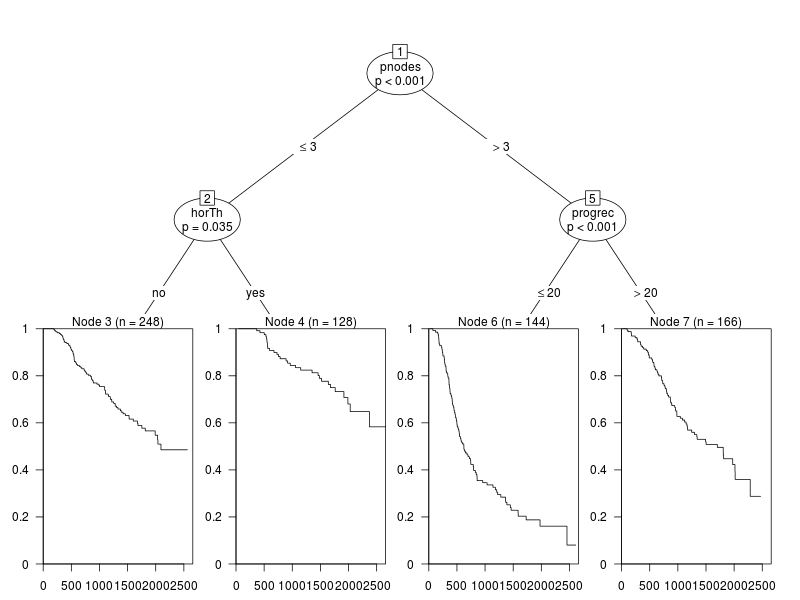
The GBSG2 data contains the data for the German Breast Cancer Study Group 2. Yes, I know, this is the second breast-related topic. It’s not a preoccupation: it’s in the documentation.
require(ipred)
data("GBSG2", package = "ipred")
We will be focusing on the recurrence free survival time of the samples. This is censored data: for some of the samples the time to recurrence is known; for others there had been no recurrence at the time of the study.
survival = Surv(GBSG2$time, event = GBSG2$cens)
head(survival, 10)
[1] 1814 2018 712 1807 772 448 2172+ 2161+ 471 2014+
head(GBSG2, 10)
horTh age menostat tsize tgrade pnodes progrec estrec time cens
1 no 70 Post 21 II 3 48 66 1814 1
2 yes 56 Post 12 II 7 61 77 2018 1
3 yes 58 Post 35 II 9 52 271 712 1
4 yes 59 Post 17 II 4 60 29 1807 1
5 no 73 Post 35 II 1 26 65 772 1
6 no 32 Pre 57 III 24 0 13 448 1
7 yes 59 Post 8 II 2 181 0 2172 0
8 no 65 Post 16 II 1 192 25 2161 0
9 no 80 Post 39 II 30 0 59 471 1
10 no 66 Post 18 II 7 0 3 2014 0
The samples for which recurrence time is not known are indicated by a “+” in the survival data. Next we construct the model and generate a plot.
GBSG2.ct plot(GBSG2.ct)
The model divides the data into four categories according to the values of three covariates: pnodes (number of positive nodes), horTh (hormonal therapy: yes or no) and progrec (progesterone receptor). The nodes reflect the distribution of survival times. For example, those samples with more than three positive nodes and progesterone receptor levels ≤ 20 had the worst distribution of survival times. Those samples with fewer than 3 nodes and that did receive hormone therapy had significantly better survival times.