Following up on my previous posts regarding the results of the Comrades Marathon, I was planning on putting together a set of models which would predict likelihood to finish and probable finishing time. Along the way I got distracted by something else that is just as interesting and which produces results which readily yield to qualitative interpretation: Conditional Inference Trees as implemented in the R package party.
Just to recall what the data look like:
head(splits.2013)
gender age.category drummond.time race.time status medal
2013-10014 Male 50-59 5.510833 NA DNF <NA>
2013-10016 Male 60-69 6.070833 NA DNF <NA>
2013-10019 Male 20-29 5.335833 11.87361 Finished Vic Clapham
2013-10031 Male 20-29 4.910833 10.94833 Finished Bronze
2013-10047 Male 50-59 5.076944 10.72778 Finished Bronze
2013-10049 Male 50-59 5.729444 NA DNF <NA>
Here the drummond.time and finish.time fields are expressed in decimal hours and correspond to the time taken to reach the half-way mark and the finish respectively. The status field indicates whether a runner finished the race or did not finish (DNF).
I am going to consider two models. The first will look at the probability of finishing and the second will look at the distribution of medals. The features which will be used to predict these outcomes will be gender, age category and half-way time at Drummond. To build the first model, first load the party library and then call ctree.
library(party)
tree.status = ctree(
status ~ gender + age.category + drummond.time, data = splits.2013,
control = ctree_control(minsplit = 750)
)
tree.status
Conditional inference tree with 17 terminal nodes
Response: status
Inputs: gender, age.category, drummond.time
Number of observations: 13917
1) drummond.time <= 5.669167; criterion = 1, statistic = 2985.908
2) drummond.time <= 5.4825; criterion = 1, statistic = 494.826
3) age.category <= 40-49; criterion = 1, statistic = 191.12
4) drummond.time <= 5.078611; criterion = 1, statistic = 76.962
5) gender == {Male}; criterion = 1, statistic = 73.4
6)* weights = 5419
5) gender == {Female}
7)* weights = 836
4) drummond.time > 5.078611
8) gender == {Male}; criterion = 1, statistic = 63.347
9) drummond.time <= 5.379722; criterion = 1, statistic = 15.55
10)* weights = 1123
9) drummond.time > 5.379722
11)* weights = 447
8) gender == {Female}
12)* weights = 634
3) age.category > 40-49
13) drummond.time <= 5.038056; criterion = 1, statistic = 68.556
14) age.category <= 50-59; criterion = 1, statistic = 40.471
15) gender == {Female}; criterion = 1, statistic = 32.419
16)* weights = 118
15) gender == {Male}
17)* weights = 886
14) age.category > 50-59
18)* weights = 170
13) drummond.time > 5.038056
19)* weights = 701
2) drummond.time > 5.4825
20) gender == {Male}; criterion = 1, statistic = 56.149
21) age.category <= 40-49; criterion = 0.995, statistic = 9.826
22)* weights = 636
21) age.category > 40-49
23)* weights = 259
20) gender == {Female}
24)* weights = 352
1) drummond.time > 5.669167
25) drummond.time <= 5.811389; criterion = 1, statistic = 301.482
26) age.category <= 30-39; criterion = 1, statistic = 37.006
27)* weights = 315
26) age.category > 30-39
28)* weights = 553
25) drummond.time > 5.811389
29) drummond.time <= 5.940556; criterion = 1, statistic = 75.164
30) age.category <= 30-39; criterion = 1, statistic = 25.519
31)* weights = 299
30) age.category > 30-39
32)* weights = 475
29) drummond.time > 5.940556
33)* weights = 694
The textual representation of the model contains a deluge of information. Making sense of this is a lot easier with a plot.
plot(tree.status)
The image below is a little small. You will want to click on it to bring up a larger version.
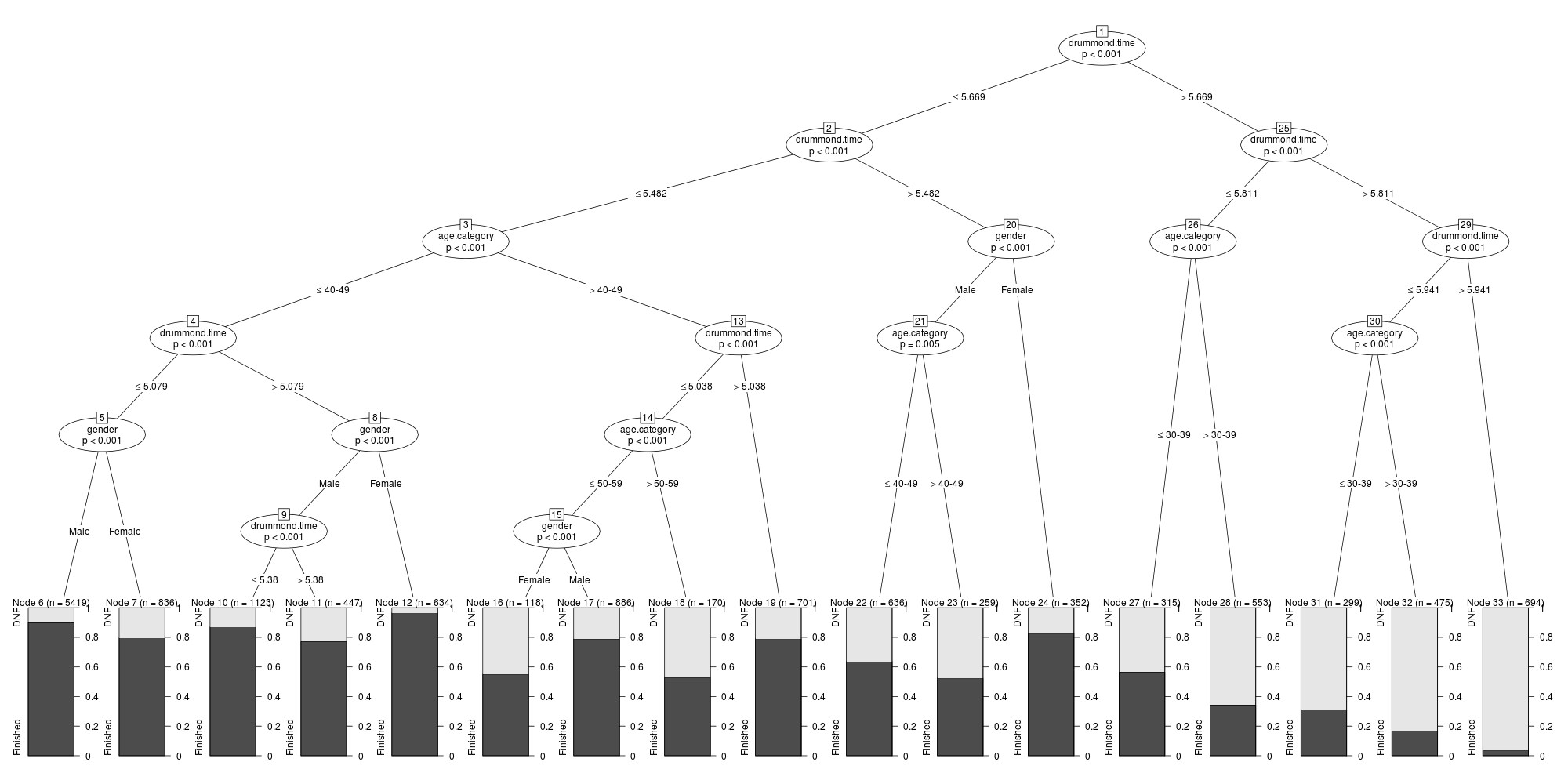
To interpret the tree, start at the top node (Node 1) labelled drummond.time, indicating that of the features considered, the most important variable in determining a successful outcome at the race is the time to the half-way mark. We are presented with two options: times that are either less than or greater than 5.669 hours. The cutoff time at Drummond is 6.167 hours (06:10:00), so runners reaching half-way after 5.669 hours are already getting quite close to the cutoff time. Suppose that we take the > 5.669 branch. The next node again depends on the half-way time, in this case dividing the population at 5.811 hours. If we take the left branch then we are considering runners who got to Drummond after 5.669 hours but before 5.811 hours. The next node depends on age category. The two branches here are for runners who are 39 and younger (left branch) and older runners (right branch). If we take the right branch then we reach the terminal node. There were 553 runners in this category and the spine plot indicates that around 35% of those runners successfully finished the race.
Rummaging around in this tree, there is a lot of interesting information to be found. For example, female runners who are aged less than 49 years and pass through Drummond in a time of between 5.079 and 5.482 hours are around 95% likely to finish the race. In fact, this is the most successful group of runners (there were 634 of them in the field). The next best group was male runners in the same age category who got to half-way in less than 5.079 hour: roughly 90% of the 5419 runners in this group finished the race.
Constructing a model for medal allocation is done in a similar fashion.
splits.2013.finishers = subset(splits.2013, status == "Finished" & !is.na(medal))
#
levels(splits.2013.finishers$medal) <- c("G", "WH", "S", "BR", "B", "VC")
Here I first extracted the subset of runners who finished the race (and for whom I have information on the medal allocated). Then, to make the plotting a little easier, the names of the levels in the medal factor are changed to a more compact representation.
tree.medal = ctree(
medal ~ gender + age.category + drummond.time, data = splits.2013.finishers,
control = ctree_control(minsplit = 750)
)
tree.medal
Conditional inference tree with 19 terminal nodes
Response: medal
Inputs: gender, age.category, drummond.time
Number of observations: 10221
1) drummond.time <= 4.124167; criterion = 1, statistic = 7452.85
2) drummond.time <= 3.438889; criterion = 1, statistic = 1031.778
3)* weights = 571
2) drummond.time > 3.438889
4) drummond.time <= 3.812222; criterion = 1, statistic = 342.628
5) drummond.time <= 3.708056; criterion = 1, statistic = 53.658
6)* weights = 549
5) drummond.time > 3.708056
7)* weights = 250
4) drummond.time > 3.812222
8) drummond.time <= 3.976111; criterion = 1, statistic = 37.853
9)* weights = 386
8) drummond.time > 3.976111
10)* weights = 431
1) drummond.time > 4.124167
11) drummond.time <= 5.043611; criterion = 1, statistic = 4144.845
12) drummond.time <= 4.55; criterion = 1, statistic = 596.673
13) drummond.time <= 4.288333; criterion = 1, statistic = 81.996
14)* weights = 603
13) drummond.time > 4.288333
15) gender == {Male}; criterion = 0.996, statistic = 10.468
16)* weights = 993
15) gender == {Female}
17)* weights = 148
12) drummond.time > 4.55
18) drummond.time <= 4.862778; criterion = 1, statistic = 77.052
19) gender == {Male}; criterion = 1, statistic = 34.077
20) drummond.time <= 4.653611; criterion = 0.994, statistic = 9.583
21)* weights = 353
20) drummond.time > 4.653611
22)* weights = 762
19) gender == {Female}
23)* weights = 237
18) drummond.time > 4.862778
24) gender == {Male}; criterion = 1, statistic = 45.95
25)* weights = 756
24) gender == {Female}
26)* weights = 193
11) drummond.time > 5.043611
27) drummond.time <= 5.265833; criterion = 1, statistic = 544.833
28) gender == {Male}; criterion = 1, statistic = 54.559
29) drummond.time <= 5.174444; criterion = 1, statistic = 26.917
30)* weights = 545
29) drummond.time > 5.174444
31)* weights = 402
28) gender == {Female}
32)* weights = 327
27) drummond.time > 5.265833
33) drummond.time <= 5.409722; criterion = 1, statistic = 88.926
34) gender == {Male}; criterion = 1, statistic = 40.693
35)* weights = 675
34) gender == {Female}
36)* weights = 277
33) drummond.time > 5.409722
37)* weights = 1763
Apologies for the bit of information overload. A plot brings out the salient information though.
plot(tree.medal)
Again you will want to click on the image below to make it legible.
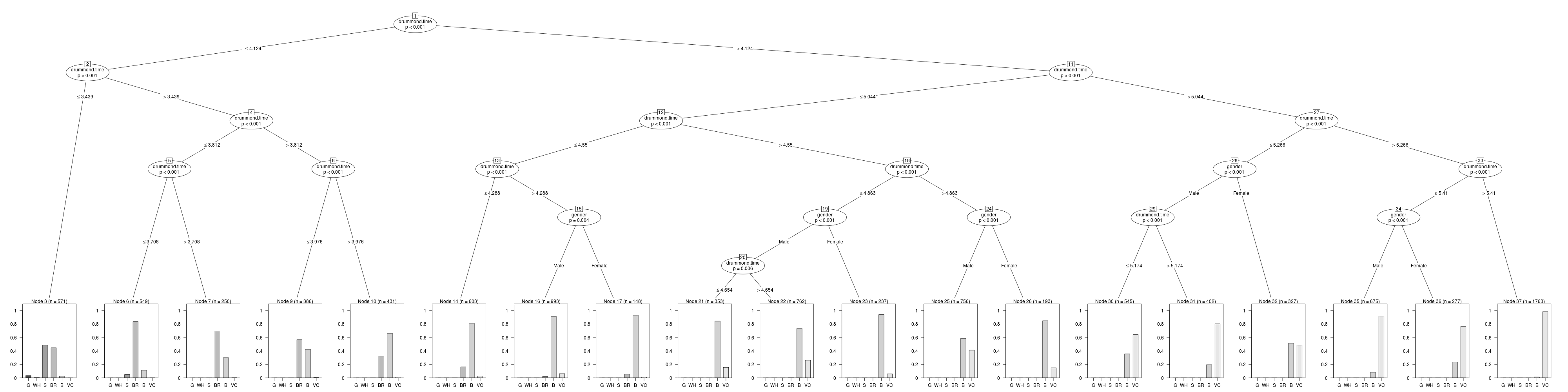
Again the most important feature is the time at the half-way mark. If we look at the terminal node on the left (Node 3), which is the only one which contains athletes who received either Gold or Wally Hayward medals, then we see that they all passed through Drummond in a time of less than 3.439 hours. Almost all of the Silver medal athletes were also in this group, along with a good number of Bill Rowan runners. A few Silver medal athletes are present in Node 6, which corresponds to runners who got to Drummond in less than 3.708 hours.
Shifting across to the other end of the plot and looking at runners who reached half-way in more than 5.266 hours. These are further divided into a group whose half-way time was more than 5.41 hours: these almost all got Vic Clapham medals. Interestingly, the outcome for athletes whose time at Drummond was greater than 5.266 hours but less than 5.41 hours depends on gender: the ladies achieved a higher proportion of Bronze medals than the men.
I could pore over these plots for hours. The take home message from this is that your outcome at the Comrades Marathon is most strongly determined by your pace in the first half of the race. Gender and age don’t seem to be particularly important, although they do exert an influence on your first half pace. Ladies who get to half-way at between 05:00 and 05:30 seem to have hit the sweet spot though with close to 100% success rate. Nice!