A client came to me with some conformance data. She was having a hard time making sense of it in a spreadsheet. I had a look at a couple of ways of presenting it that would bring out the important points.
The Data
The data came as a spreadsheet with multiple sheets. Each of the sheets had a slightly different format, so the easiest thing to do was to save each one as a CSV file and then import them individually into R.
After some preliminary manipulation, this is what the data looked like:
dim(P)
[1] 1487 17
names(P)
[1] "date" "employee" "Sorting Colour" "Extra Material"
[5] "Fluff" "Plate Run Blind" "Plate Maker" "Colour Short"
[9] "Stock Issued Short" "Catchup" "Carton Marked" "Die Cutting"
[13] "Glueing" "Damaged Stock" "Folding Problem" "Sorting Setoff"
[17] "Bad Lays"
head(P[, 1:7])
date employee Sorting Colour Extra Material Fluff Plate Run Blind Plate Maker
1 2011-01-11 E01 0 1 0 0 0
2 2011-01-11 E01 0 1 0 0 0
3 2011-01-11 E37 0 0 0 0 0
4 2011-01-11 E41 0 1 0 0 0
5 2011-01-12 E42 0 1 0 0 0
6 2011-01-17 E01 0 1 0 0 0
Each record indicates the number of incidents per date and employee for each of 15 different manufacturing problems. The names of the employees have been anonymised to protect their dignities.
My initial instructions were something to the effect of “Don’t worry about the dates, just aggregate the data over years” (I’m paraphrasing, but that was the gist of it). As it turns out, the date information tells us something rather useful. But more of that later.
Employee / Problem View
I first had a look at the number of incidences of each problem per employee.
library(reshape2)
library(plyr)
Q = melt(P, id.vars = c("employee", "date"), variable.name = "problem")
#
# Remove "empty" rows (non-events)
#
Q = subset(Q, value == 1)
#
Q$year = strftime(Q$date, "%Y")
Q$DOW = strftime(Q$date, "%A")
Q$date <- NULL
head(Q)
employee problem value year DOW
46 E11 Sorting Colour 1 2011 Friday
47 E15 Sorting Colour 1 2011 Friday
53 E26 Sorting Colour 1 2011 Friday
67 E26 Sorting Colour 1 2011 Monday
68 E26 Sorting Colour 1 2011 Monday
70 E01 Sorting Colour 1 2011 Tuesday
To produce the tiled plot that I was after, I first had to transform the data into a tidy format. To do this I used melt() from the reshape2 library. I then derived year and day of week (DOW) columns from the date column and deleted the latter.
Next I used ddply() from the plyr package to consolidate the counts by employee, problem and year.
problem.table = ddply(Q, .(employee, problem, year), summarise, count = sum(value))
head(problem.table)
employee problem year count
1 E01 Sorting Colour 2011 17
2 E01 Sorting Colour 2012 2
3 E01 Sorting Colour 2013 2
4 E01 Extra Material 2011 50
5 E01 Extra Material 2012 58
6 E01 Extra Material 2013 13
Time to make a quick plot to check that everything is on track.
library(ggplot2)
ggplot(problem.table, aes(x = problem, y = employee, fill = count)) +
geom_tile(colour = "white") +
xlab("") + ylab("") +
facet_grid(. ~ year) +
geom_text(aes(label = count), angle = 0, size = rel(3)) +
scale_fill_gradient(high="#FF0000" , low="#0000FF") +
theme(panel.background = element_blank(), axis.text.x = element_text(angle = 45, hjust = 1)) +
theme(legend.position = "none")
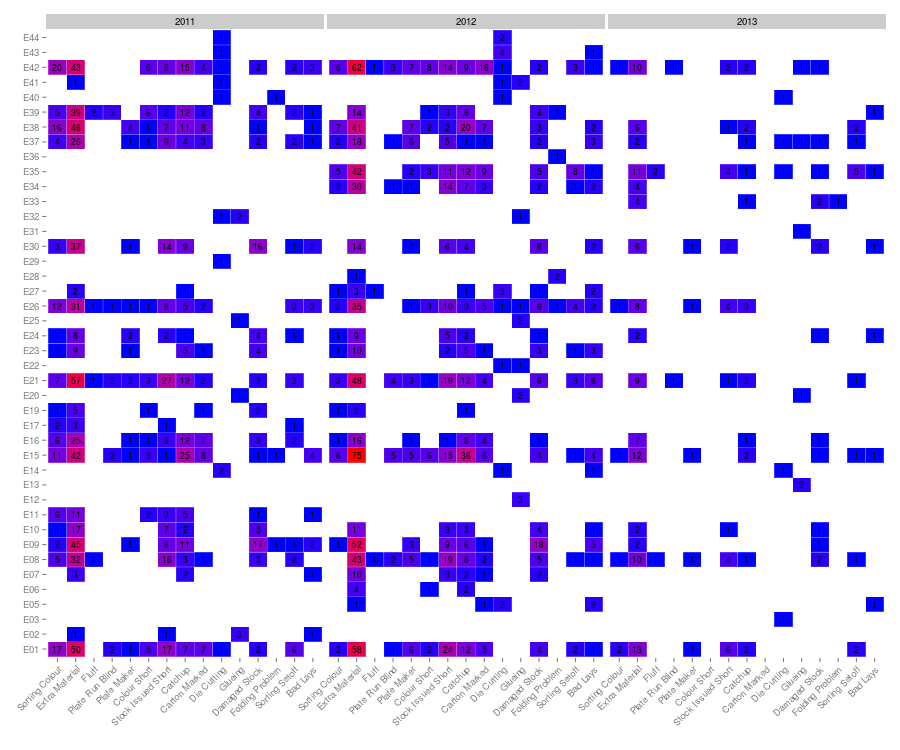
That’s not too bad. Three panels, one for each year. Employee names on the y-axis and problem type on the x-axis. The colour scale indicates the number of issues per year, employee and problem. Numbers are overlaid on the coloured tiles because apparently the employees are a little pedantic about exact figures!
But it’s all a little disorderly. It might make more sense it we sorted the employees and problems according to the number of issues. First generate counts per employee and per problem. Then sort and extract ordered names. Finally use the ordered names when generating factors.
CEMPLOYEE = with(problem.table, tapply(count, employee, sum))
CPROBLEM = with(problem.table, tapply(count, problem, sum))
#
FEMPLOYEE = names(sort(CEMPLOYEE, decreasing = TRUE))
FPROBLEM = names(sort(CPROBLEM, decreasing = TRUE))
problem.table = transform(problem.table,
employee = factor(employee, levels = FEMPLOYEE),
problem = factor(problem, levels = FPROBLEM)
)
The new plot is much more orderly.
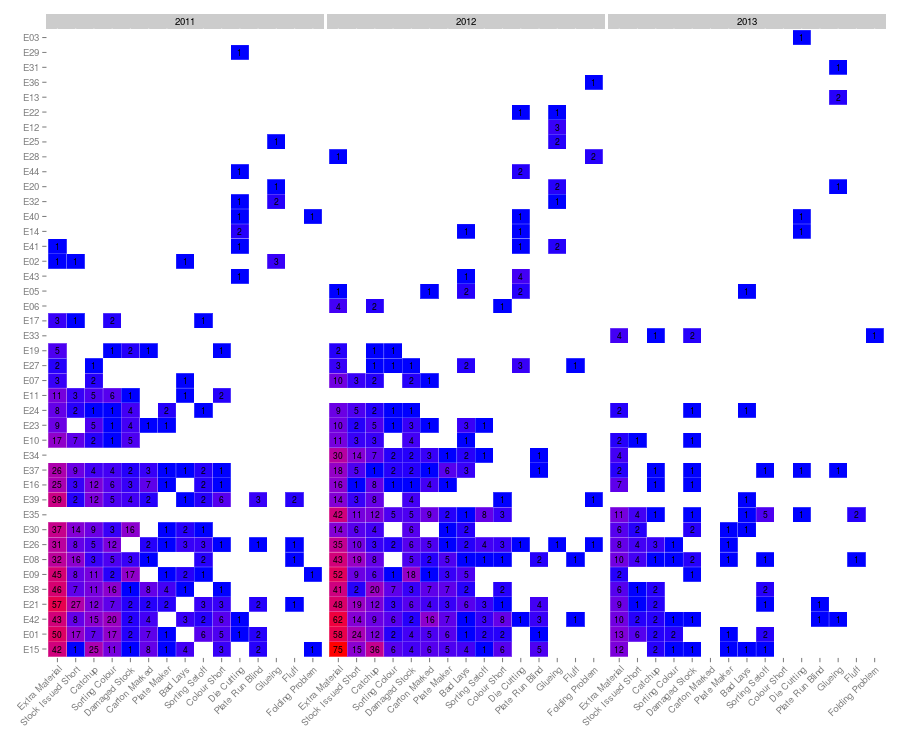
We can easily see who the worst culprits are and what problems crop up most often. The data for 2013 don’t look as bad as the previous years, but the year is not complete and the counts have not been normalised.
Employee / Day of Week View
Although I had been told to ignore the date information, I suspected that there might be something interesting in there: perhaps some employees perform worse on certain days of the week?
Using ddply() again, I consolidated the counts by day of week, employee and year.
problem.table = ddply(Q, .(DOW, employee, year), summarise, count = sum(value))
Then generated a similar plot.
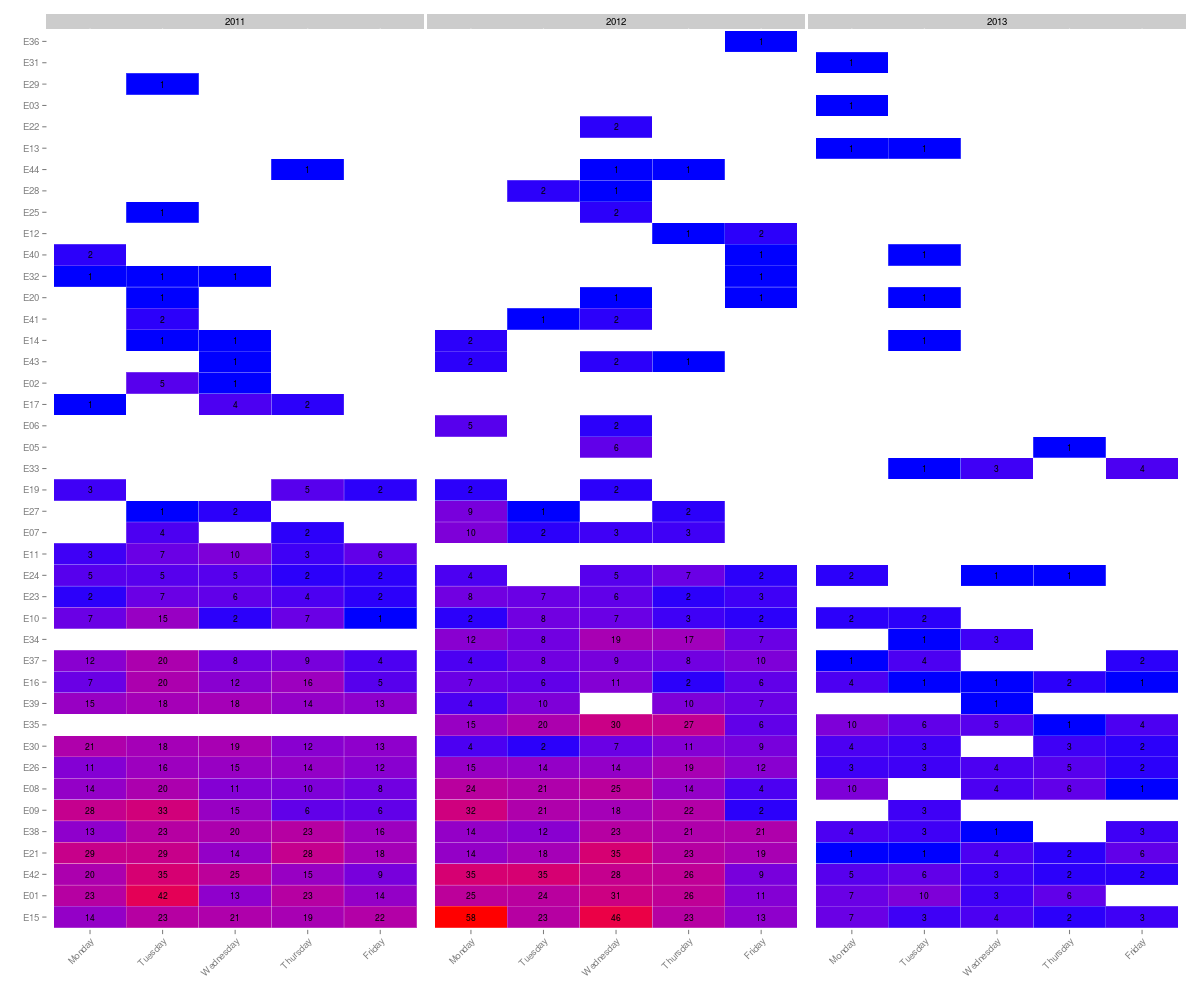
Now that’s rather interesting: for a few of the employees there is a clear pattern of poor performance at the beginning of the week.
Conclusion
I am not sure what my client is going to do with these plots, but it seems to me that there is quite a lot of actionable information in them, particularly with respect to which of her employees perform poorly on particular days of the week and in doing some specific tasks.