The Wonders of {foreach}
{foreach} package which makes it easy to perform calculations in parallel with R.
Writing code from scratch to do parallel computations can be rather tricky. However, the packages providing parallel facilities in R make it remarkably easy. One such package is foreach. I am going to document my trail of discovery with foreach, which began some time ago, but has really come into fruition over the last few weeks.
First we need a reproducible example. Preferably something which is numerically intensive.
max.eig <- function(N, sigma) {
d <- matrix(rnorm(N**2, sd = sigma), nrow = N)
#
E <- eigen(d)$values
#
abs(E)[[1]]
}This function generates a square matrix of uniformly distributed random numbers, finds the corresponding (complex) eigenvalues and then selects the eigenvalue with the largest modulus. The dimensions of the matrix and the standard deviation of the random numbers are given as input parameters.
max.eig(5, 1)[1] 2.180543max.eig(5, 1)[1] 1.922373Since the data are random, each function call yields a different result.
Vectorised
It would be interesting to look at the distribution of these results. We can produce a multitude of such results using vectorised multiple invocations of the function.
E = sapply(1:10000, function(n) {max.eig(5, 1)})
summary(E) Min. 1st Qu. Median Mean 3rd Qu. Max.
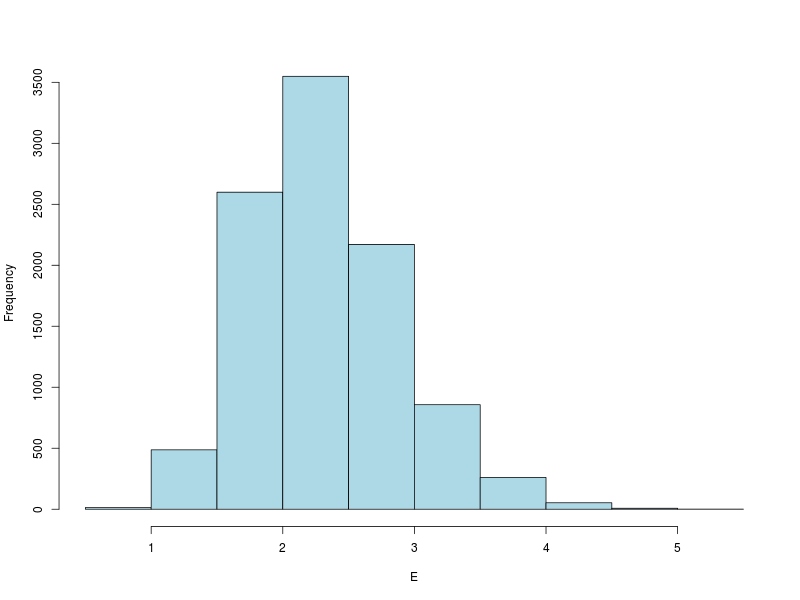
0.7615 1.9150 2.2610 2.3160 2.6470 5.2800Here eigenvalues are calculated from 10000 function calls, all of which use the same parameters. The distribution of the resulting eigenvalues is plotted in the histogram below. Generating these data took a couple of seconds on my middle-of-the-range laptop. Not a big wait. But it was only using one of the four cores on the machine, so in principle it could have gone faster.
We can make things more interesting by varying the dimensions of the matrix.
sapply(1:5, function(n) {max.eig(n, 1)})[1] 0.1107296 2.4150209 1.5316894 1.4639843 1.5902372Or changing both the dimensions (taking on integral values between 1 and 5) and the standard deviation (running through 1, 2 and 3).
sapply(1:5, function(n) {sapply(1:3, function(m) {max.eig(n, m)})}) [,1] [,2] [,3] [,4] [,5]
[1,] 1.6510105 0.5055719 2.053653 3.100523 2.440287
[2,] 0.3927822 0.4253438 2.936822 2.567797 4.057999
[3,] 5.8680964 2.9921687 3.571913 9.384722 3.827924The results are presented in an intuitive matrix. Everything up to this point is being done serially.
Enter foreach
> library(foreach)At first sight, the foreach library provides a slightly different interface for vectorisation. We’ll start off with simple repetition.
times(10) %do% max.eig(5, 1)[1] 1.936434 1.679151 2.507670 2.547832 2.292036 2.783489 2.545161 2.370996 2.904912 3.063622That just executes the function with the same arguments 10 times over. If we want to systematically vary the parameters, then instead of times() we use foreach().
foreach(n = 1:5) %do% max.eig(n, 1)[[1]]
[1] 0.4220093
[[2]]
[1] 0.8011105
[[3]]
[1] 1.45409
[[4]]
[1] 2.345526
[[5]]
[1] 1.846834The results are returned as a list, which is actually more reminiscent of the behaviour of lapply() than sapply(). But we can get something more compact by using the .combine option.
foreach(n = 1:5, .combine = c) %do% max.eig(n, 1)[1] 1.758172 2.601491 1.132095 2.106668 2.280279That’s better. Now, what about varying both the dimensions and standard deviation? We can string together multiple calls to foreach() using the %:% nesting operator.
foreach(n = 1:5) %:% foreach(m = 1:3) %do% max.eig(n, m)I have omitted the output because it consists of nested lists: it’s long and somewhat ugly. But again we can use the .combine option to make it more compact.
> foreach(n = 1:5, .combine = rbind) %:% foreach(m = 1:3) %do% max.eig(n, m) [,1] [,2] [,3]
result.1 0.2602969 1.285972 6.455814
result.2 1.113325 4.203023 6.828937
result.3 1.28568 2.711026 4.338442
result.4 1.222587 4.88346 6.826418
result.5 1.722572 6.197047 5.878693foreach(n = 1:5, .combine = cbind) %:% foreach(m = 1:3) %do% max.eig(n, m) result.1 result.2 result.3 result.4 result.5
[1,] 0.4667732 1.234185 1.280043 2.081554 2.591618
[2,] 0.3897914 2.407168 2.030388 3.190009 3.865416
[3,] 1.637852 6.867441 2.927759 8.144164 8.688782You can choose between combining using cbind() or rbind() depending on whether you want the output from the inner loop to form the columns or rows of the output. There’s lots more magic to be done with .combine. You can find the details in the informative article Using The foreach Package by Steve Weston.
You can also use foreach() to loop over multiple variables simultaneously.
foreach(n = 1:5, m = 1:5) %do% max.eig(n, m)[[1]]
[1] 0.2448898
[[2]]
[1] 3.037161
[[3]]
[1] 4.313644
[[4]]
[1] 11.49438
[[5]]
[1] 9.850941But this is still all serial…
Filtering
One final capability before we move on to parallel execution, is the ability to add in a filter within the foreach() statement.
library(numbers)
foreach(n = 1:100, .combine = c) %:% when (isPrime(n)) %do% n[1] 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97Here we identify the prime numbers between 1 and 100 by simply looping through the entire sequence of values and selecting only those that satisfy the condition in the when() clause. Of course, there are more efficient ways to do this, but this notation is rather neat.
Going Parallel
Making the transition from serial to parallel is as simple as changing %do% to %dopar%.
foreach(n = 1:5) %dopar% max.eig(n, 1)[[1]]
[1] 0.7085695
[[2]]
[1] 2.358641
[[3]]
[1] 2.492679
[[4]]
[1] 1.24261
[[5]]
[1] 1.993046
Warning message:
executing %dopar% sequentially: no parallel backend registeredThe warning gives us pause for thought: maybe it was not quite that simple? Yes, indeed, there are additional requirements. You need first to choose a parallel backend. And here, again, there are a few options. We will start with the most accessible, which is the multi-core backend.
Multi-core
Multi-core processing is provided by the doMC library. You need to load the library and tell it how many cores you want to use.
library(doMC)
registerDoMC(cores=4)Let’s make a comparison between serial and parallel execution times.
library(doMC)
registerDoMC(cores=4)Let’s make a comparison between serial and parallel execution times.
library(rbenchmark)
benchmark(
foreach(n = 1:50) %do% max.eig(n, 1),
foreach(n = 1:50) %dopar% max.eig(n, 1)
) test replications elapsed relative user.self sys.self user.child sys.child
1 foreach(n = 1:50) %do% max.eig(n, 1) 100 15.723 1.618 15.721 0.000 0.000 0.000
2 foreach(n = 1:50) %dopar% max.eig(n, 1) 100 9.720 1.000 2.537 0.732 17.589 4.436The overall execution time is reduced, but not by the factor of 4 that one might expect. This is due to the additional burden of having to distribute the job over the multiple cores. The tradeoff between communication and computation is one of the major limitations of parallel computing, but if computations are lengthy and there is not too much data to move around then the gains can be excellent.
On a single machine you are limited by the number of cores. But if you have access to a cluster then you can truly take things to another level.
Cluster
The foreach() functionality can be applied to a cluster using the doSNOW library. We will start by using doSNOW to create a collection of R instances on a single machine using a SOCK cluster.
library(doSNOW)
cluster = makeCluster(4, type = "SOCK")
registerDoSNOW(cluster)
benchmark(
foreach(n = 1:50) %do% max.eig(n, 1),
foreach(n = 1:50) %dopar% max.eig(n, 1)
) test replications elapsed relative user.self sys.self user.child sys.child
1 foreach(n = 1:50) %do% max.eig(n, 1) 100 14.052 1.284 14.089 0.00 0 0
2 foreach(n = 1:50) %dopar% max.eig(n, 1) 100 10.943 1.000 4.856 0.06 0 0
> #
> stopCluster(cluster)The improvement in execution time is roughly comparable to what we got with the multi-core implementation. Note that when you are done, you need to shut down the cluster.
Next we will create an MPI cluster consisting of 20 threads.
cluster = makeCluster(20, type = "MPI")
#
registerDoSNOW(cluster)
#
benchmark(
foreach(n = 1:100) %do% max.eig(n, 1),
foreach(n = 1:100) %dopar% max.eig(n, 1)
) test replications elapsed relative user.self sys.self user.child sys.child
1 foreach(n = 1:100) %do% max.eig(n, 1) 100 62.111 3.114 62.105 0.000 0 0
2 foreach(n = 1:100) %dopar% max.eig(n, 1) 100 19.943 1.000 19.939 0.001 0 0The parallel job runs roughly 3 times quicker.
How about a slightly more complicated example? We will try running some bootstrap calculations. We start out with the serial implementation.
random.data <- matrix(rnorm(1000000), ncol = 1000)
bmed <- function(d, n) median(d[n])
library(boot)
sapply(1:100, function(n) {sd(boot(random.data[, n], bmed, R = 10000)$t)}) [1] 0.03959383 0.03705808 0.04345169 0.04027020 0.04038000 0.05223590
[7] 0.04238710 0.03780378 0.03158105 0.04990962 0.03533659 0.04369453
[13] 0.04268809 0.03905804 0.04213135 0.03996430 0.04406709 0.04104289
[19] 0.03970051 0.04600647 0.03246924 0.04691756 0.03842184 0.04490416
[25] 0.04186847 0.04438831 0.04127071 0.03891882 0.03047418 0.03638098
[31] 0.05250030 0.03841815 0.05274663 0.03883077 0.03425073 0.04040601
[37] 0.03424269 0.03531023 0.04018262 0.03151492 0.03342666 0.03742966
[43] 0.04937554 0.03497177 0.04394860 0.03767637 0.02899806 0.04270962
[49] 0.04088265 0.03809354 0.03927284 0.03844624 0.03456490 0.04081791
[55] 0.03875243 0.04397634 0.04147273 0.03937905 0.03670778 0.03159038
[61] 0.04563407 0.03438879 0.04191963 0.04736964 0.04071846 0.04237484
[67] 0.03437641 0.03939834 0.03492293 0.03902924 0.03777660 0.04770606
[73] 0.04097508 0.04040914 0.04188157 0.03584112 0.04030294 0.03580566
[79] 0.03357913 0.03319093 0.04652214 0.04150011 0.03612597 0.03582600
[85] 0.03911643 0.04717892 0.03998664 0.04566421 0.03753487 0.03868689
[91] 0.03837865 0.04003132 0.03136855 0.03592450 0.03633709 0.04108870
[97] 0.04439740 0.04032455 0.03027182 0.04239404First we generated a big array of normally distributed random numbers. Then we used sapply() to calculate bootstrap estimates for the standard deviation of the median for each columns of the matrix.
The parallel implementation requires a little more work: first we need to make the global data (the random matrix and the bootstrap function) available across the cluster.
clusterExport(cluster, c("random.data", "bmed"))Then we spread the jobs out over the cluster nodes. We will do this first using clusterApply(), which is part of the snow library and is the cluster analogue of sapply(). It returns a list, so to get a nice compact representation we use unlist().
results = clusterApply(cluster, 1:100, function(n) {
library(boot)
sd(boot(random.data[, n], bmed, R = 10000)$t)
})
head(unlist(results))[1] 0.03879663 0.03722502 0.04283553 0.03963994 0.04067666 0.05230591The foreach implementation is a little neater.
results = foreach(n = 1:100, .combine = c) %dopar% {
library(boot); sd(boot(random.data[, n], bmed, R = 10000)$t)
}
head(results)[1] 0.03934909 0.03742790 0.04307101 0.03969632 0.03994723 0.05211977stopCluster(cluster)The key in both cases is that the boot library must be loaded on each of the cluster nodes as well so that its functionality is available. Simply loading the library on the root node is not enough!
Conclusion
Using the parallel computing functionality in R via the foreach package has completely transformed my workflow. Jobs that have previously run for a few days on my desktop machine now complete in a few hours on a 128 node cluster.