I got quite inspired by the EXIF with R post on the Timely Portfolio blog and decided to do a similar analysis with my photographic database.
The Data
The EXIF data were dumped using exiftool.
find 1995/ 20* -type f -print0 | xargs -0 exiftool -S -FileName -Orientation -ExposureTime \
-FNumber -ExposureProgram -ISO -CreateDate -ShutterSpeedValue -ApertureValue -FocalLength \
-MeasuredEV -FocusDistanceLower -FocusDistanceUpper | tee image-data.txt
This command uses some of the powerful features of BASH. If you are interested in seeing more about these, take a look at shell-fu and commandfu.
The resulting data were a lengthy series of records (one for each image file) that looked like this:
======== 2003/02/18/PICT0040.JPG
FileName: PICT0040.JPG
Orientation: Horizontal (normal)
ExposureTime: 1/206
FNumber: 8.4
ExposureProgram: Program AE
ISO: 50
CreateDate: 2003:02:18 23:11:35
FocalLength: 16.8 mm
======== 2003/07/02/100-0006.jpg
FileName: 100-0006.jpg
Orientation: Horizontal (normal)
ExposureTime: 1/250
FNumber: 8.0
ISO: 50
CreateDate: 2003:07:02 11:14:58
ShutterSpeedValue: 1/251
ApertureValue: 8.0
FocalLength: 6.7 mm
MeasuredEV: 14.91
FocusDistanceLower: 0 m
FocusDistanceUpper: inf
The data for each image begin at the “========” separator and the number of fields varies according to what information is available per image.
Getting the Data into R
The process of importing the data into R and transforming it into a workable structure took a little bit of work. Nothing too tricky though.
data = readLines("data/image-data.txt")
data = paste(data, collapse = "|")
data = strsplit(data, "======== ")[[1]]
data = strsplit(data, "|", fixed = TRUE)
data = data[sapply(data, length) > 0]
Basically, here I loaded all of the data using readLines() which gave me a vector of strings. I then concatenated all of those strings into a single very, very long string. I sliced this up into blocks using the separator string “======== " and then split the records in each block at the pipe symbol “|”. Finally, I found that the results had a few empty elements which I simply discarded.
The resulting data looked like this:
sample(data, 3)
[[1]]
[1] "2008/10/26/img_0570.jpg" "FileName: img_0570.jpg" "Model: Canon DIGITAL IXUS 60"
[4] "Orientation: Horizontal (normal)" "ExposureTime: 1/800" "FNumber: 2.8"
[7] "ISO: 82" "CreateDate: 2008:10:26 16:10:16" "ShutterSpeedValue: 1/807"
[10] "ApertureValue: 2.8" "FocalLength: 5.8 mm" "MeasuredEV: 14.12"
[13] "FocusDistanceLower: 0 m" "FocusDistanceUpper: 4.23 m"
[[2]]
[1] "2012/08/07/IMG_8766.JPG" "FileName: IMG_8766.JPG" "Model: Canon EOS 500D"
[4] "Orientation: Horizontal (normal)" "ExposureTime: 1/8" "FNumber: 2.8"
[7] "ExposureProgram: Program AE" "ISO: 800" "CreateDate: 2012:08:07 18:03:42"
[10] "ShutterSpeedValue: 1/8" "ApertureValue: 2.8" "FocalLength: 17.0 mm"
[13] "MeasuredEV: 2.88" "FocusDistanceLower: 0.42 m" "FocusDistanceUpper: 0.44 m"
[[3]]
[1] "2011/05/11/IMG_7355.CR2" "FileName: IMG_7355.CR2" "Model: Canon EOS 500D"
[4] "Orientation: Horizontal (normal)" "ExposureTime: 1/500" "FNumber: 9.5"
[7] "ExposureProgram: Program AE" "ISO: 800" "CreateDate: 2011:05:11 17:51:04"
[10] "ShutterSpeedValue: 1/512" "ApertureValue: 9.5" "FocalLength: 23.0 mm"
[13] "MeasuredEV: 12.62" "FocusDistanceLower: 0.51 m" "FocusDistanceUpper: 0.54 m"
The next step was to reformat the data in each of these records and consolidate into a data frame.
extract <- function(d) {
# Remove file name (redundant since it is also in first named record)
d <- d[-1]
#
d <- strsplit(d, ": ")
#
# This list looks like
#
# [[1]]
# [1] "FileName" "DIA_0095.jpg"
#
# [[2]]
# [1] "CreateDate" "1995:06:23 09:09:54"
#
# We want to convert it into a key-value list...
#
as.list(setNames(sapply(d, function(n) {n[2]}), sapply(d, function(n) {n[1]})))
}
data <- lapply(data, extract)
Note the use of the handy utility function setNames() which was used to avoid creating a temporary variable. The result is a list, each element of which is a sub-list with named fields. A typical element looks like
data[500]
[[1]]
[[1]]$FileName
[1] "dscf0271.jpg"
[[1]]$Model
[1] "FinePix A340"
[[1]]$Orientation
[1] "Horizontal (normal)"
[[1]]$ExposureTime
[1] "1/60"
[[1]]$FNumber
[1] "2.8"
[[1]]$ExposureProgram
[1] "Program AE"
[[1]]$ISO
[1] "100"
[[1]]$CreateDate
[1] "2004:12:25 06:18:36"
[[1]]$ShutterSpeedValue
[1] "1/64"
[[1]]$ApertureValue
[1] "2.8"
[[1]]$FocalLength
[1] "5.7 mm"
The next step was to concatenate all of these elements to form a single data frame. Normally I would do this using a combination of do.call() and rbind() but this will not work for the present case because the named lists for each of the images do not all contain the same set of fields. Instead I used ldply(), which deals with this situation gracefully.
library(plyr)
#
data = ldply(data, function(d) {as.data.frame(d)})
The final data, after a few more minor manipulations, is formatted as a neat data frame.
tail(data)
FileName Model CreateDate Orientation ExposureTime FNumber ExposureProgram ISO
30151 IMG_2513.JPG Canon EOS 500D 2013-10-05 13:40:27 Rotate 270 CW 125 5.6 Program AE 400
30152 IMG_2515.JPG Canon EOS 500D 2013-10-05 13:40:29 Rotate 270 CW 125 5.6 Program AE 400
30153 IMG_2517.JPG Canon EOS 500D 2013-10-05 13:40:45 Rotate 270 CW 125 5.6 Program AE 400
30154 IMG_2519.JPG Canon EOS 500D 2013-10-05 13:40:48 Rotate 270 CW 125 5.6 Program AE 400
30155 IMG_2523.JPG Canon EOS 500D 2013-10-05 13:40:57 Rotate 270 CW 125 5.6 Program AE 400
30156 IMG_2525.JPG Canon EOS 500D 2013-10-05 13:41:00 Rotate 270 CW 125 5.6 Program AE 400
FocalLength ShutterSpeedValue ApertureValue MeasuredEV FocusDistanceLower FocusDistanceUpper
30151 20 125 5.6 10.25 2.57 3.18
30152 21 125 5.6 10.25 2.57 3.18
30153 23 125 5.6 10.50 2.57 3.18
30154 25 125 5.6 10.25 2.57 3.18
30155 17 125 5.6 10.38 2.57 3.18
30156 21 125 5.6 10.25 2.57 3.18
Plots and Analysis
How many photographs are there?
dim(data)
[1] 21031 14
The only sensible way to understand my photography habits is to produce some visualisations. The three elements in the exposure triangle are ISO, shutter speed (or exposure time) and aperture (or F-number). I try to always shoot at the lowest ISO, so the two variables of interest are shutter speed and aperture.
First let’s look at mosaic and association plots for these two variables.
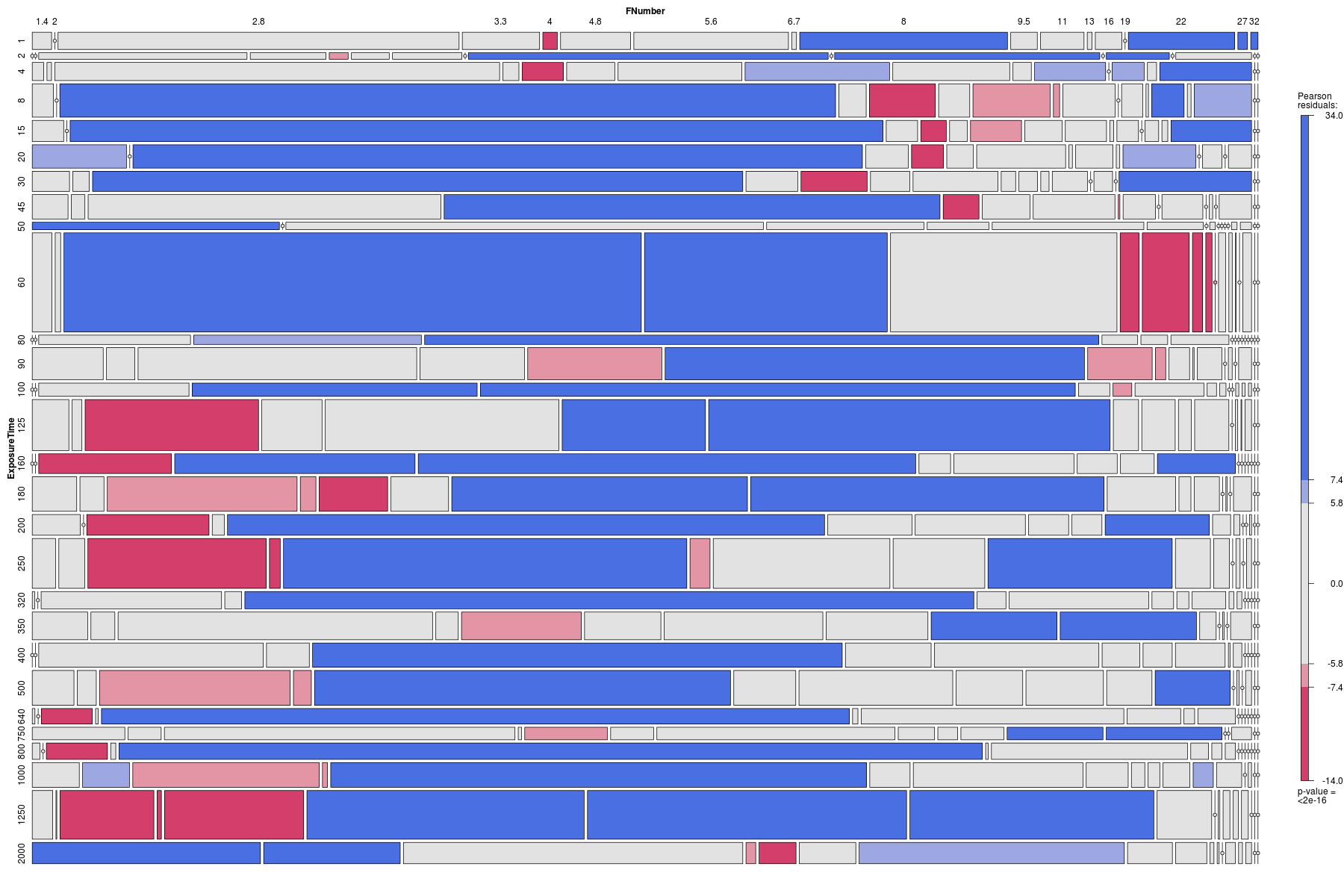
Mosaic plots are a powerful way of understanding multivariate categorical data. The mosaic plot above indicates the relative frequency of photographs with particular combinations of shutter speed and aperture. The large blue block in the tenth row from the top indicates that there are many photographs at 1/60 second and F/2.8. Whereas the small blue block on the right of the top row indicates that there are relatively few photographs at 1 second and F/32. The colour shading in the plot indicates whether there are too many (blue) or too few (red) photographs with a given combination of shutter speed and aperture relative to the assumption that these two variables are independent [1,2]. Grey blocks are not inconsistent with the assumption of independence. Since there are a significant number of blue and red blocks, the data suggests that there is a significant relationship between shutter speed and aperture (which is just what one would expect!).
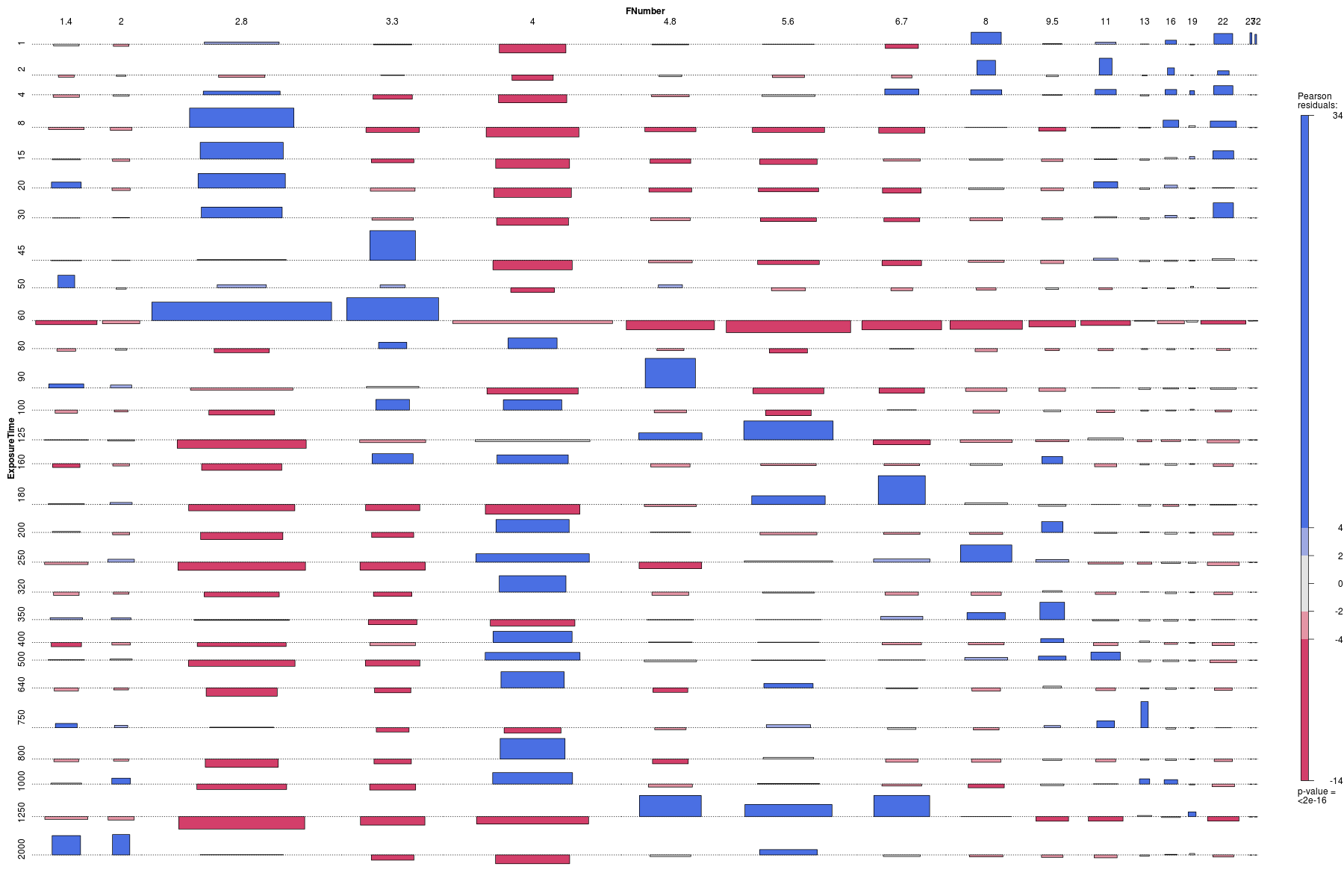
The association plot provides essentially the same information, with the area of a block being positive (blue and above the line) or negative (red and below the line) according to whether or not the observed data are greater than or less than what would be expected in the case of independence.
A somewhat simpler way of looking at these data is a heat map, which just gives the number of counts for each combination of shutter speed and aperture and does not make any model comparisons. It is presented on a regular grid, which makes it a little easier on the mind too (although it is appreciably weaker in terms of information content).
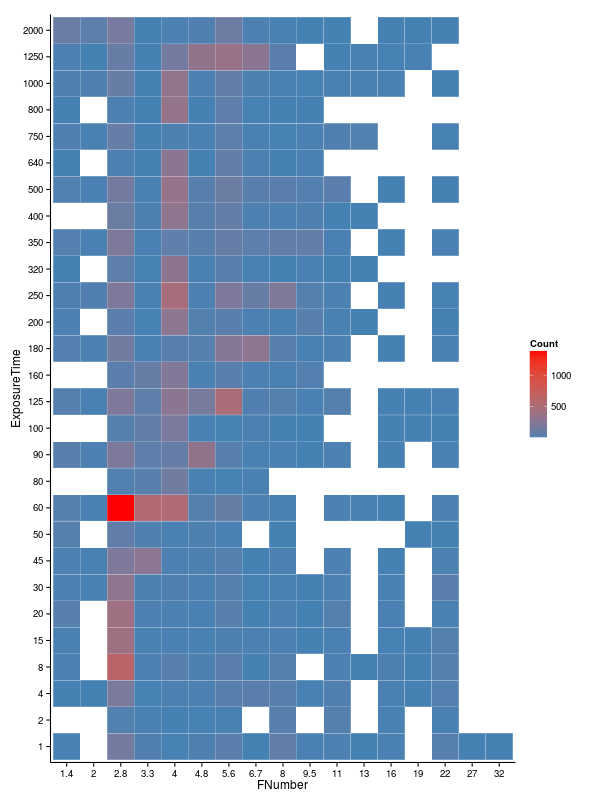
Again we can see that the overwhelming majority of my photographs have been taken at 1/60 second and F/2.8, which I am ashamed to say shows a distinct lack of imagination! (Note to self to remedy this situation).
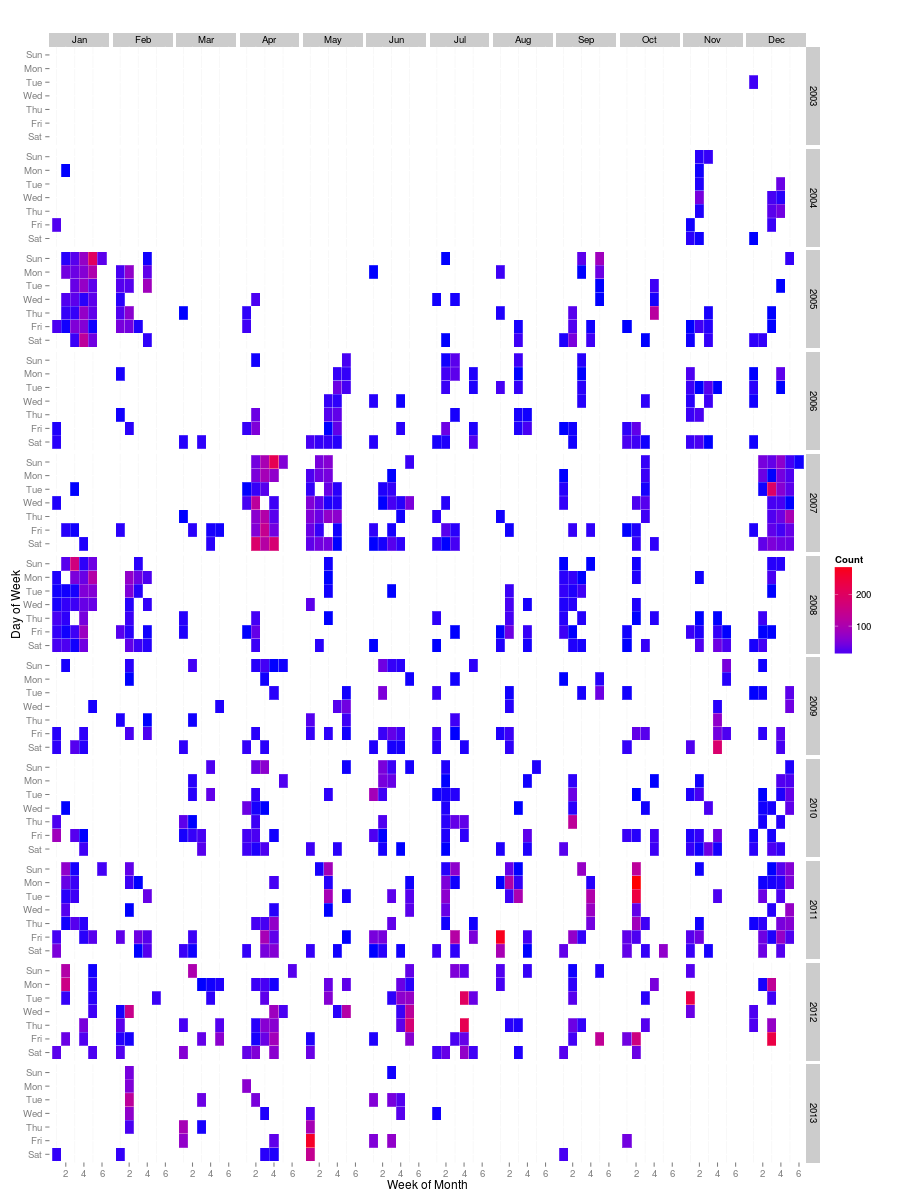
And, finally, another heat map which shows how the number of photographs I have taken has evolved over time. There have been some very busy periods like the (southern hemisphere) summers of 2004/5 and 2007/8 when I went to Antarctica, and April/May 2007 when I visited Marion Island.
References
- Zeileis, Achim, David Meyer, and Kurt Hornik. “Residual-based Shadings in vcd.”
- Visualizing contingency tables