I have just been trying to import some data into R. The data were exported from a SQL Server client in tab-separated value (TSV) format. However, reading the data into R the “usual” way produced unexpected results:
data <- read.delim("sample-query.tsv", header = FALSE, stringsAsFactors = FALSE)
head(data)
V1 V2
1 7E51B3EC4263438B22811BE78391A823 2129
2 8617E5E557903C7FAF011FBE2DFCED1D 3518
3 1E8B37DFB143BEEEE052516D2F3B58F5 6018
4 60B8AA536CFD26C5B5CF5BA6D7B7893C 7811
5 5A3BA8589DCD62B31948DC2715CA3ED9 12850
6 3552BF8AF58A58C794A43D4AA21F4FBA 13284
Those weird characters in the first record… where did they come from? They don’t show up in a text editor, so they’re not easy to edit out.
Googling ensued and revealed that those weird characters were in fact the byte order mark (BOM), special characters which indicate the endianness of the file. This was quickly confirmed using CYGWIN. (Yes, shamefully, I am working under Windows at the moment!)
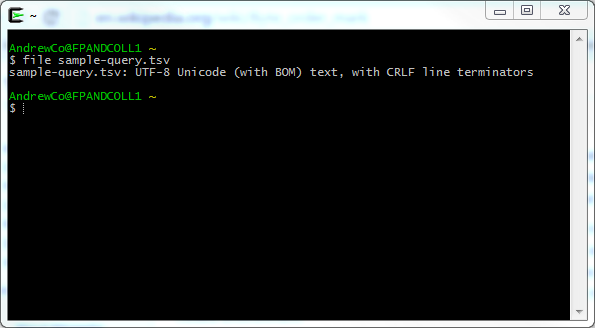
The solution is remarkably simple: just specify the correct character encoding.
data <- read.delim("sample-query.tsv", header = FALSE, stringsAsFactors = FALSE, fileEncoding = "UTF-8-BOM")
head(data)
V1 V2
1 7E51B3EC4263438B22811BE78391A823 2129
2 8617E5E557903C7FAF011FBE2DFCED1D 3518
3 1E8B37DFB143BEEEE052516D2F3B58F5 6018
4 60B8AA536CFD26C5B5CF5BA6D7B7893C 7811
5 5A3BA8589DCD62B31948DC2715CA3ED9 12850
6 3552BF8AF58A58C794A43D4AA21F4FBA 13284
Problem solved.