On my final day at ICML I attended the Workshop on Machine Learning Open Source Software: Open Ecosystems. The topics included not only Open Source Software (OSS) for doing Machine Learning but also researchers publishing their work under an Open Source model. The latter is obviously good for Science!
Extending the Numeric Python ecosystem beyond in-memory computing (Matthew Rocklin, @mrocklin)
Python has issues. One of the biggest is the Global Interpreter Lock (GIL), which prevents simultaneous manipulation of Python objects by different threads.
Dask falls around the middle of the implementation continuum for parallel programming, somewhere between high and low levels of abstraction. It has an interface which mimics that of Numpy. Dask arrays are like Numpy arrays but are divided into chunks to facilitate parallel computation. Any operations on the Dask array are automatically done in parallel (across all available cores). The image below is an animated GIF produced by Dask illustrating the execution of a parallel job.
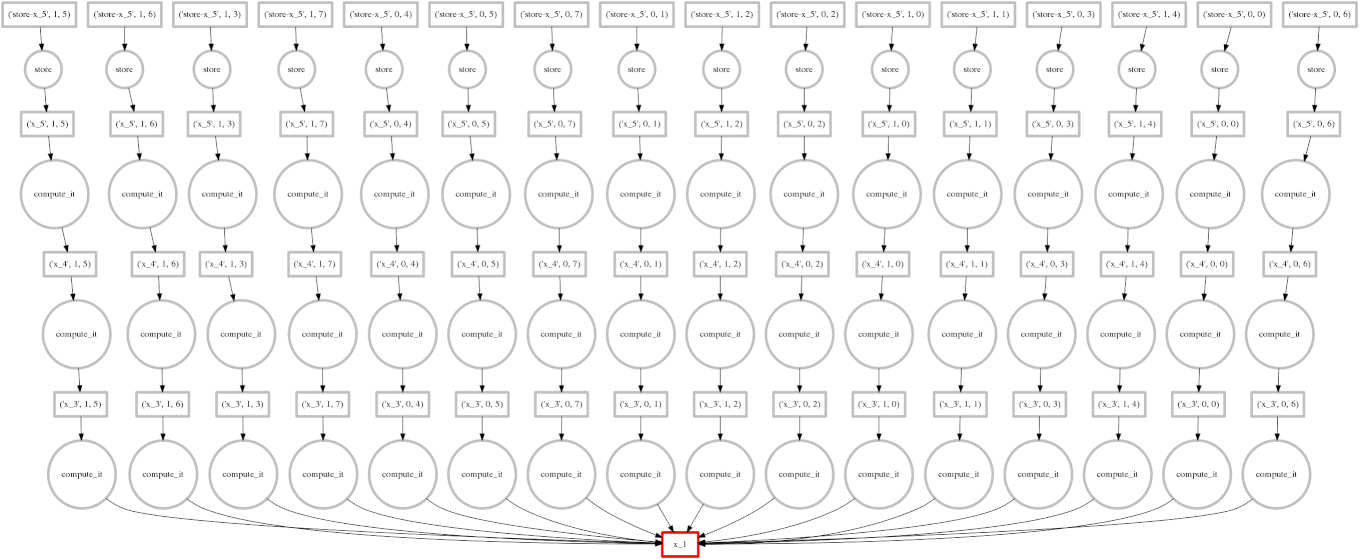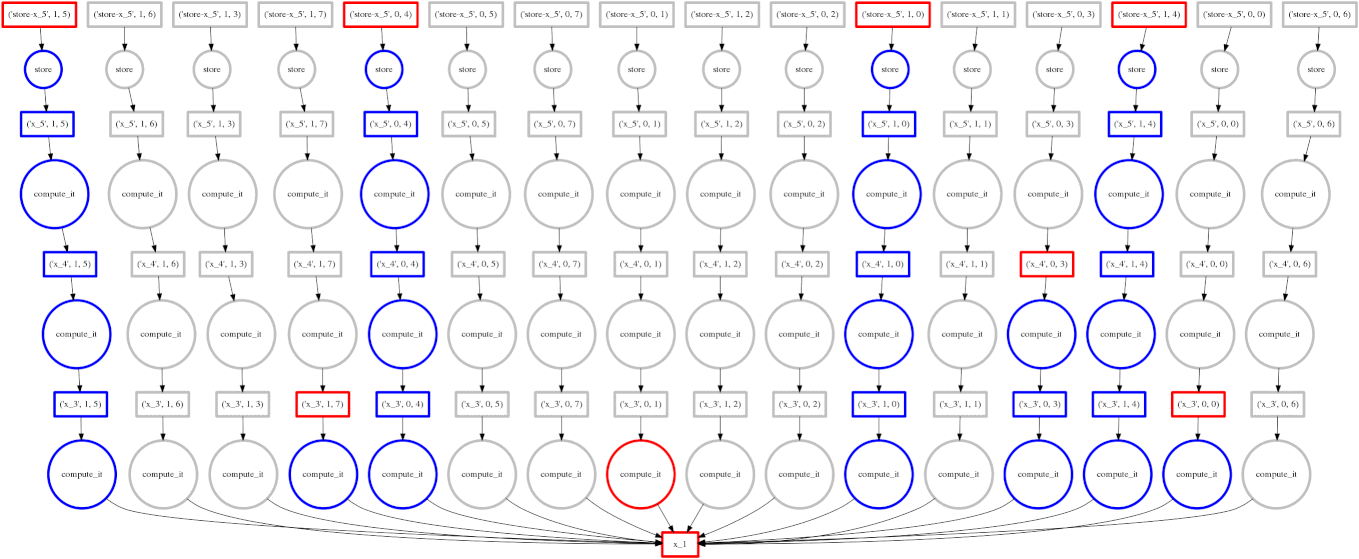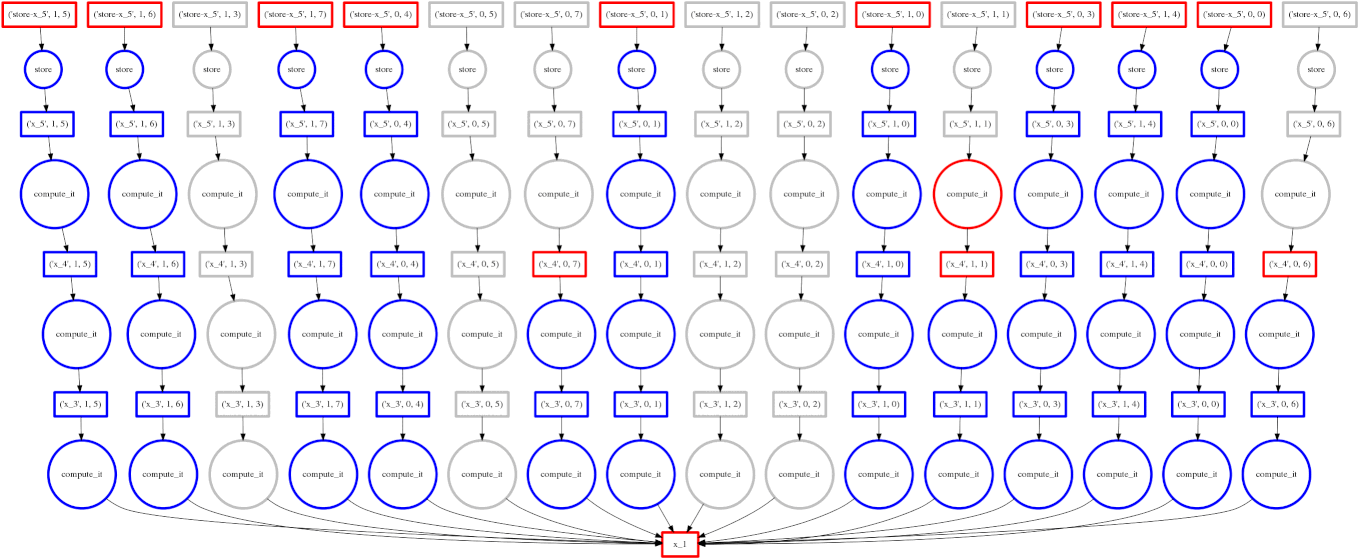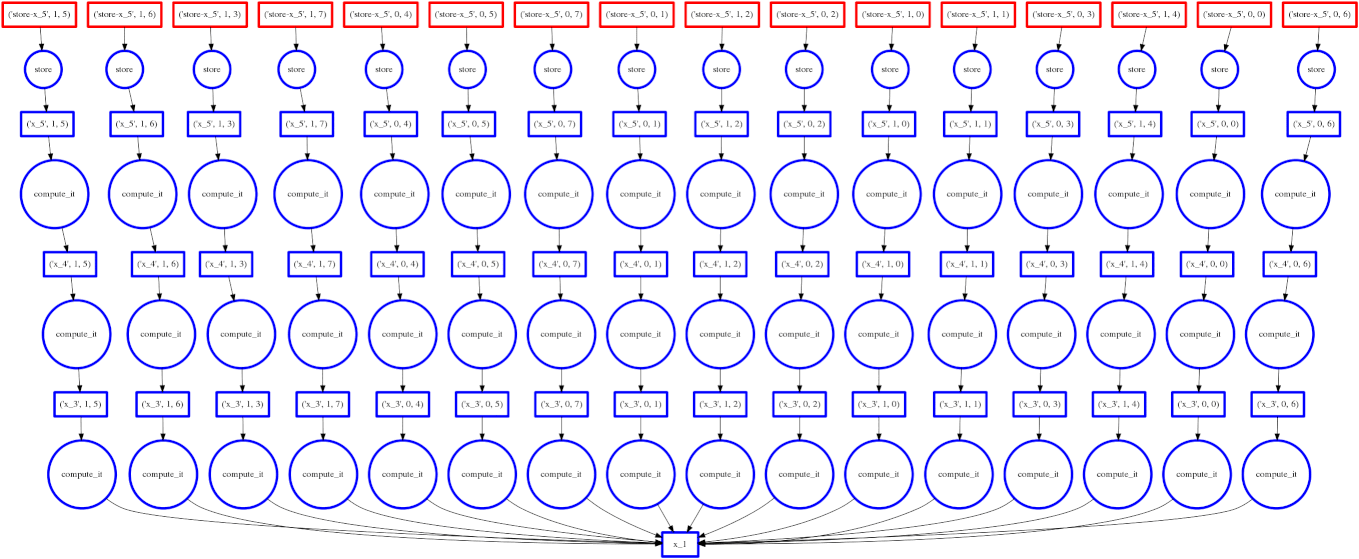
Collaborative Filtering via Matrix Decomposition in mlpack (Ryan R. Curtin)
mlpack is a machine learning library written in C++. The design goals for mlpack are
- scalable and fast implementation of a wide range of ML algorithms;
- an interface that is manageable for non-experts.
The code is template based (similar to the Armadillo C++ Linear Algebra Library).
mlpack comes with a simple command line tool which does Collaborative Filtering.
$ cf -i MovieLens-100k.csv -R 10 -q query.csv -a RegSVD -n 10Of course, under the hood this tool is implemented using the mlpack library.
BLOG: A Probabilistic Programming Language
Described BLOG, a scripting language for specifying ML problems. Examples presented were
- coin flipping;
- Bayesian Linear Regression;
- Kalman Filter;
- LDA.
Blitz Talks for Posters
A series of short talks introducing the various posters on display:
- nilearn: Machine learning for Neuro-Imaging in Python;
- KeLP: Kernel-based Learning Platform in Java;
- Automatic Differentiation;
- FAST toolkit for Hidden Markov Models;
- OpenML: An online Machine Learning Community.
Julia’s Approach to Open Source Machine Learning (John Myles White)
Julia is a high-level language for high-performance technical computing. It is not strongly typed. Instead it has a rich “expressive” type system, including things like immutable and parametric types. It is fully unicode compliant, which allows you to have variable names like Θ, Φ or even 🎩.
Although it is not necessary to explicitly declare types, it is important to think about types because they can have a large impact on performance. You have the freedom to do whatever you want (at least, as far as types are concerned), but Julia will not guarantee that the resulting code will be any good. “Julia is a compiler that should never yell at you.” So, designing code for Julia requires careful thought.
Julia does Just in Time (JIT) compilation. Function code_native will display the machine code generated by the Julia JIT compiler for any function.
All of the code, including packages, is on GitHub. Testing is done with Travis and code coverage is measured with Coveralls.
More information on the language can be found at Julia: A fresh approach to numerical computing and Julia: A Fast Dynamic Language for Technical Computing.
Caffe: Community Architecture for Fast Feature Embedding
Caffe is an Open Source framework for Deep Learning. Somewhat ironically the “hard” problem in the xkcd comic below was solved quite rapidly using Caffe.

Caffe is written in C++ but has command line, MATLAB and Python interfaces. It runs on both CPU and GPU.
Caffe has a Model Zoo where trained models can be posted.
From flop to success in academic software development (Gaël Varoquaux)
“Most lines of code written by programmers in academia never reach an audience.”
Gaël has been involved in a number of relatively high profile software projects including Sckikit-learn, Mayavi and joblib.
Computational Science (versus Computer Science) is the use of computers and mathematical models to address scientific research in a range of domains. But how to choose a good computational science problem? Tricky question. Find a need. Then define scope and vision. Target a problem that will yield other contributors and then share the common code. The contributions of others will make your code better over time.
Six steps:
- Focus on quality;
- Make good documentation and examples;
- Use GitHub;
- Limit technicality and focus on the key issues (refer to scope and vision);
- Packaging and releases are important;
- Acknowledge contributors and give credit.
Other ruminations:
- Choose your weapons. Python is a good one.
- Scriptability is important.
- Strive for Quality. Do less but do it better. Be consistent.
Pareto principle: 80% of your use cases can be solved with 20% of the code.
And that was the end of my conference!
Below is a word cloud that I put together from the PDFs of the conference papers.
<img src=“https://datawookie.dev/blog/2015/07/constructing-a-word-cloud-for-icml-2015/word-cloud.png” width=“100%” alt=“Word cloud based on terms extracted from PDFs associated with the ICML conference
Well, that’s a wrap for ICML 2015. Take a look at the word cloud I created, which summarises the whole event rather nicely.