I read Data Mining with Rattle and R by Graham Williams over a year ago. It’s not a new book and I’ve just been tardy in writing up a review. That’s not to say that I have not used the book in the interim: it’s been on my desk at work ever since and I’ve dipped into it from time to time. As a reference for ongoing analyses it’s an extremely helpful resource.

This book focuses on the use of Rattle, an interface to R, for Data Mining. Before I take a look at its contents, here are some specifics: it was published in 2011 by Springer-Verlag; it’s part of the Use R! series; 374 pages in length; DOI 10.1007/978-1-4419-9890-3.
Part I: Explorations
- Introduction
Some general background information on Data Mining, outlining the typical path of a Data Mining project. Also discusses appropriate tools and why R+Rattle is a good combination. - Getting Started
Instructions on getting both R and Rattle up and running. Breeze through an introductory example, from loading data and exploratory analysis to building models and evaluating results. Finishes with a more in-depth review on some aspects of the R language, with a useful section on using environments for encapsulation. - Working with Data
Looking at various issues pertaining to data: where it comes from, quality and documentation. - Loading Data
Getting data into Rattle from various sources (including the clipboard, directly from the WWW, CSV or tab delimited files and ODBC). Then partitioning those data into training and testing sets as well as assigning roles to variables. - Exploring Data
A deeper look at exploratory data analysis on single variables using techniques ranging from numeric and textual summaries to visualisation with histograms, scatter, bar, dot, box and mosaic plots. Relationships between variables are considered using correlation matrices and hierarchical clustering. - Interactive Graphics
What extra information can be extracted from the data using interactive tools likelatticistand GGobi? - Transforming Data
Data transformation is often the largest task in an analysis project. The issues of cleaning and dealing with missing data and outliers are dealt with. Scaling and non-linear transformation of the data are considered. Finally the chapter takes a look at variable recoding via binning of continuous variables or creating indicator variables.
Part II: Building Models
- Descriptive and Predictive Analytics
- Cluster Analysis
- Association Analysis
- Decision Trees
- Random Forests
- Boosting
- Support Vector Machines
The first chapter in this part of the book describes the distinction between descriptive and predictive analytics, and acts as an introduction to building models in Rattle. Each of the following six chapters considers a different type of model. The chapter on association analysis uses data on DVD purchases while the remaining chapters all use the weather data set (from the rattle package) for illustration. Each chapter starts with a high level (mostly) qualitative description of how the model works and an overview of the algorithm. This is followed by a detailed tutorial showing how the model is applied in Rattle. The details of achieving the same analysis via the R console are then presented. Having both of these perspectives is extremely helpful. Details of various parameters used to fine tune the model round out each chapter.
Part III: Delivering Performance
- Model Performance Evaluation
There's a distinct part of the Rattle interface for dealing with the important topic of model evaluation. It provides access to a range of evaluation methods extending from simple metrics like precision and recall based on a confusion matrix through to risk charts and ROC curves. - Deployment
Various options for deploying a Rattle model, ranging from a deployment in R to exporting PMML and converting to a stand alone model.
Part IV: Appendices
A. Installing Rattle
How to install Rattle (predicated on an existing R installation).
B. Sample Datasets
The datasets which come along with the Rattle package and a discussion of how these data were acquired and processed. This is a valuable portion of the book since it documents the entire data preparation pipeline.
There’s an extensive set of references and a complete index.
Since I enjoy being close to the raw, bleeding edge I re-installed the beta version of Rattle today and gave it a spin.
library(devtools)
devtools::install_bitbucket("kayontoga/rattle")
library(rattle)
Rattle: A free graphical interface for data mining with R.
Version 4.0.0 Copyright (c) 2006-2015 Togaware Pty Ltd.
Type 'rattle()' to shake, rattle, and roll your data.
rattle()
The GUI looks pretty sleek. I did have hassles with some of the functionality in the beta version, so if you are going to give this a try I’d advise you to just install the version available at CRAN.
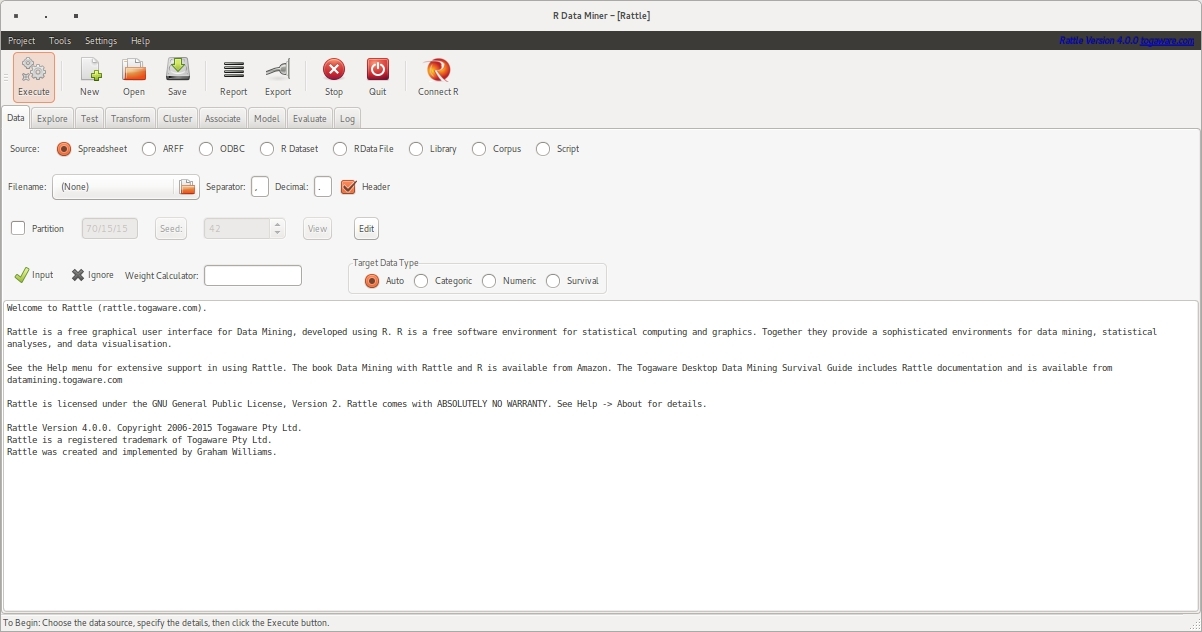
Wrapping things up, Data Mining with Rattle and R is not just about how to use Rattle to solve Data Mining problems. It also digs quite deep into a number of Data Mining and Machine Learning algorithms. As such it’s also a pretty handy reference. If you are looking at a way of transitioning from a point-and-click style analysis to R, then I think that installing Rattle and getting hold of a copy of this book would be a good place to start. I think that the key thing to consider with regards to this book is that it does not set out to be an encyclopaedia on Machine Learning. It’s focus is on using Rattle (and in the process it provides the necessary background information).