A question posed by one of my colleagues: can a checksum be used to guess message length? My immediate response was negative and, as it turns out, a simple simulation supported this knee-jerk reaction.
Here’s the situation: a piece of software has been written to process a stream of messages. Each message is a sequence of bytes, where the length of the sequence varies, and is terminated by a checksum byte, which is calculated as the cumulative bitwise XOR of the message bytes. There is no header information specifying the length of the sequence. Is it possible to use the checksum byte to locate the end of each message?
It seems like this might just be feasible. But there’s a problem: a coincidental match would cause a premature end to a message. To illustrate this point, let’s look at an example. Consider a message composed of the following series of bytes:
154 59 161 111 127 182 227 37 8 170 194
Now look at the checksums generated from the message as each new byte arrives.
154 161 0 111 16 166 69 96 104 194
The first byte in the message is 154, so the checksum is just 154. The second byte in the message is 59, which doesn’t match the checksum so we proceed to recalculate the checksum for the first two bytes, which is now 161. The third byte in the message is 161, which just happens to match the checksum! If we were using the checksum to determine the message length then we’d (wrongly) conclude that the message had come to an end.
Our ad hoc method for determining message length would have failed for this message in particular. But there would also be a knock-on effect because failing to correctly identify the end of one message would also mean incorrectly identifying the beginning of the next message, so the whole sequence of messages and checksums would get out of whack. That’s a far bigger problem. In the interests of simplicity we’ll just focus on the failure rate for a single message.
The quickest way to estimate the failure rate for our ad hoc system is simulation. I generated a population of randomised messages of increasing length and then calculated the expected failure rate as a function of message length. The results are plotted below with the message length on the x-axis and probability of falsely identifying a byte in the message as the checksum byte on the y-axis. The blue like is the average failure rate from the simulations and the orange band represents the 95% binomial confidence interval. I consolidated all failures per message. For example, it’s possible that a particular message might have more than one point at which the checksum byte could be mistaken. This is simply counted as a single failure.
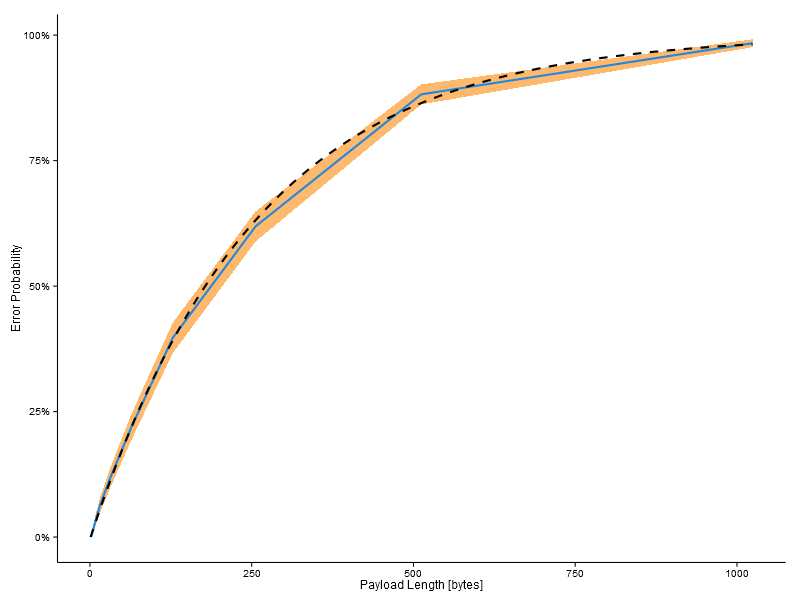
According to these results, the likelihood of failure is relatively small if the messages are short. For example, a message of 16 bytes would have a 6% failure rate. However, as the messages get longer the likelihood of mistakenly identifying a checksum byte escalates significantly. By the time that the message is 256 bytes long the likelihood of a mistake is 65%. For messages of practical lengths this is not going to be a feasible proposition.
Update: A theoretical curve (courtesy of a comment from Christine) has been added to the plot.