
One of the things I like most about web scraping is that almost every site comes with a new set of challenges.
The Accordion Concept
I recently had to scrape a few product pages from the site of a large retailer. I discovered that these pages use an “accordion” to present the product attributes. Only a single panel of the accordion is visible at any one time. For example, you toggle the Details panel open to see the associated content.
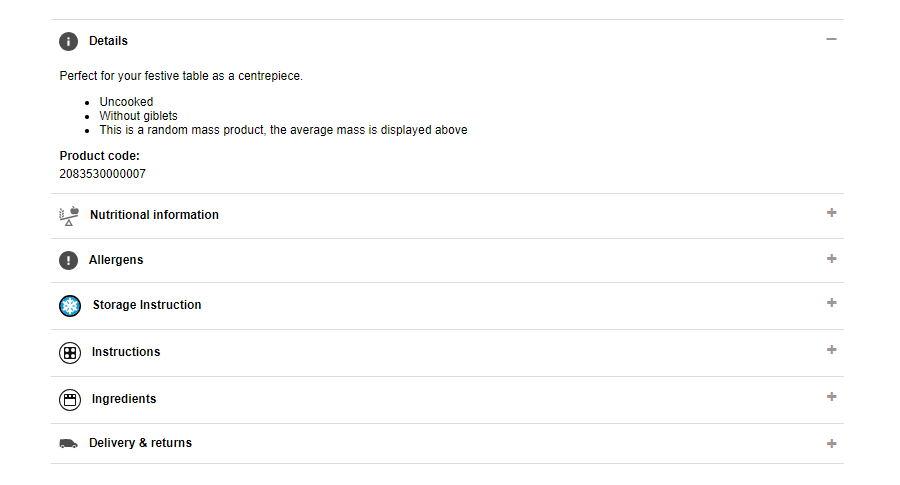
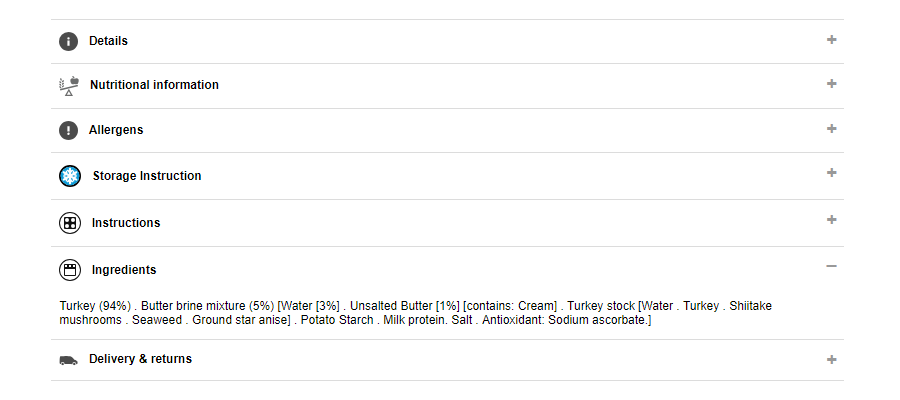
To see the Ingredients panel, you toggle that one open. However, when it opens, the Details panel immediately closes. There is only ever one panel open at a time.
A bit of research reveals that there are a few ways to implement an accordion, all of which rely on CSS or JavaScript (or, most commonly, a combination of the two).
The Accordion Implementation
Those that are implemented in CSS alone are a relatively easy target for scraping because the content of all of the panels is always accessible on the page.
Bringing JavaScript into the mix can make things appreciably more complicated: when the content of a panel is not visible, it’s probably not even present in the page source. This, of course, means that it’s inaccessible to a scraper (if it’s not in the page then you cannot scrape it!). You can see this effect clearly in the HTML code (below). The active panel (framed in red) has content in the inner div. The inactive panels all have class is-collapsed and for each of them the inner div is empty.

Scraping the Accordion
I wanted to scrape the content of each of the accordion panels. Since the entire accordion is rendered in JavaScript, static scraping tools are hopeless. Thankfully there are alternatives like Splash and Selenium. I used the latter via the RSelenium package.
Once you’ve figured out how the accordion is built, the scraping is relatively simple.
-
Fire up a Selenium Docker container. I’m using
selenium/standalone-chrome-debug:3.11. -
Create a
remoteDriverinstance (mine is calledbrowser) and run theopen()method. -
Use the
navigate()method to open the web page. -
Locate the elements on the page which contain the accordion panels.
# Select the accordion panels. accordion <- browser$findElements(using = 'css selector', '.accordion > .accordion__segment') -
Loop through each of these elements, expanding the corresponding panel and scraping the required content.
lapply(accordion, function(panel) { # Locate the toggle. toggle <- panel$findChildElement(using = 'css selector', '.accordion__toggle') # Expand section (toggle if it is currently collapsed). if (str_detect(toggle$getElementAttribute("class")[[1]], "is-collapsed")) toggle$clickElement() # Extract content from the panel! })
It makes sense to wrap the final three steps up in a function so that they can be applied systematically to one or more pages. I’m returning a tibble for each panel and then using bind_rows() to concatenate them all into a single tibble.