The transcripts for the South African President’s speeches are available here. I’ve just added these data to the {saffer} package.
library(saffer)Let’s take a look.
glimpse(president_speeches)Rows: 621
Columns: 6
$ date <date> 2016-01-07, 2016-01-21, 2016-01-23, 2016-02-06, 2016-02-09, …
$ position <chr> "Deputy President", "President", "Deputy President", "Preside…
$ person <chr> "Cyril Ramaphosa", "Jacob Zuma", "Cyril Ramaphosa", "Jacob Zu…
$ language <chr> "en", "en", "en", "en", "en", "en", "en", "en", "en", "en", "…
$ title <chr> "Deputy President Cyril Ramaphosa’s Address to the Extra-Ordi…
$ text <chr> "Comrade Chairperson of the SPLM and President of the Republi…We’ll focus on speeches made in English by Cyril Ramaphosa in his position as President. We’ll also retain only the date and text fields.
ramaphosa <- president_speeches %>%
filter(
person == "Cyril Ramaphosa",
position == "President",
language == "en"
) %>%
select(date, text)
# How many speeches?
#
nrow(ramaphosa)[1] 296We’re going to use the {tidytext} package to perform some simple analyses.
library(tidytext)Break the text into tokens.
ramaphosa <- ramaphosa %>%
unnest_tokens(
word,
text,
to_lower = TRUE
)# A tibble: 475,603 × 2
date word
<date> <chr>
1 2018-02-16 speaker
2 2018-02-16 of
3 2018-02-16 the
4 2018-02-16 national
5 2018-02-16 assembly
6 2018-02-16 ms
7 2018-02-16 baleka
8 2018-02-16 mbete
9 2018-02-16 chairperson
10 2018-02-16 of
# … with 475,593 more rowsI can already see that there are some terms in there that I’d like to exclude. Let’s load the stop word list that comes with {tidytext} and add in some custom stop words.
data(stop_words)
stop_words <- rbind(
stop_words %>% select(word),
tibble(
word = c(
"ms"
)
)
)Now remove the stop words, punctuation and all numbers.
ramaphosa <- ramaphosa %>%
anti_join(stop_words, by = "word") %>%
mutate(
word = str_replace_all(word, "[:punct:]", "")
) %>%
filter(
!str_detect(word, "^[:digit:]+$")
)What are the most common words and how often do they occur?
(ramaphosa_count <- ramaphosa %>% count(word, sort = TRUE))# A tibble: 15,044 × 2
word n
<chr> <int>
1 south 2650
2 people 2322
3 africa 2047
4 economic 1291
5 country 1221
6 african 1206
7 development 1155
8 government 1019
9 investment 970
10 women 886
# … with 15,034 more rows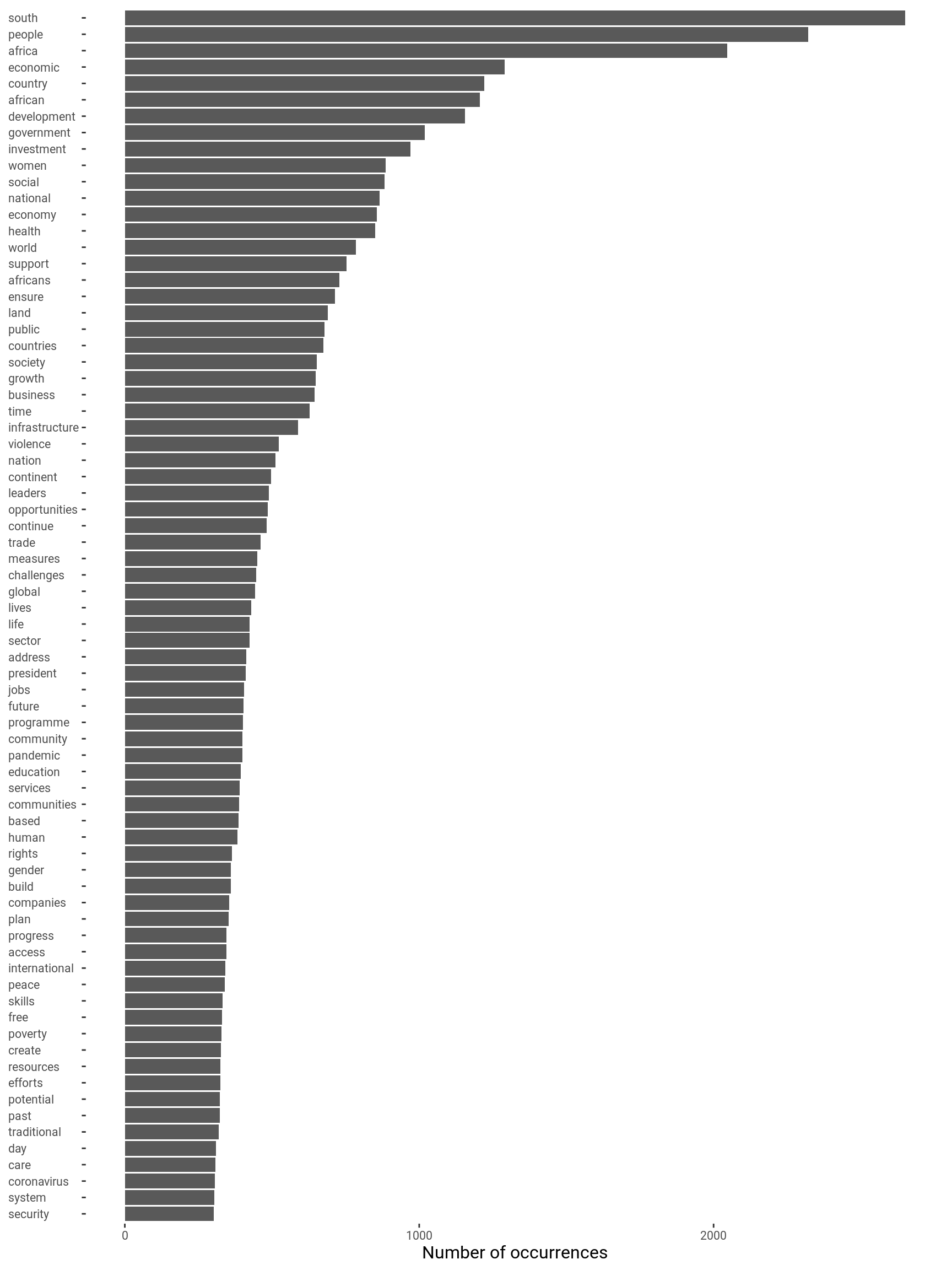
Who can resist a word cloud, right? We’ll create one using the versatile {ggwordcloud} package.

Interesting. But this doesn’t give us any indication of how topical issues have changed over time. Let’s look at this in another way. The plot below shows the cumulative proportional contribution of individual terms over time.
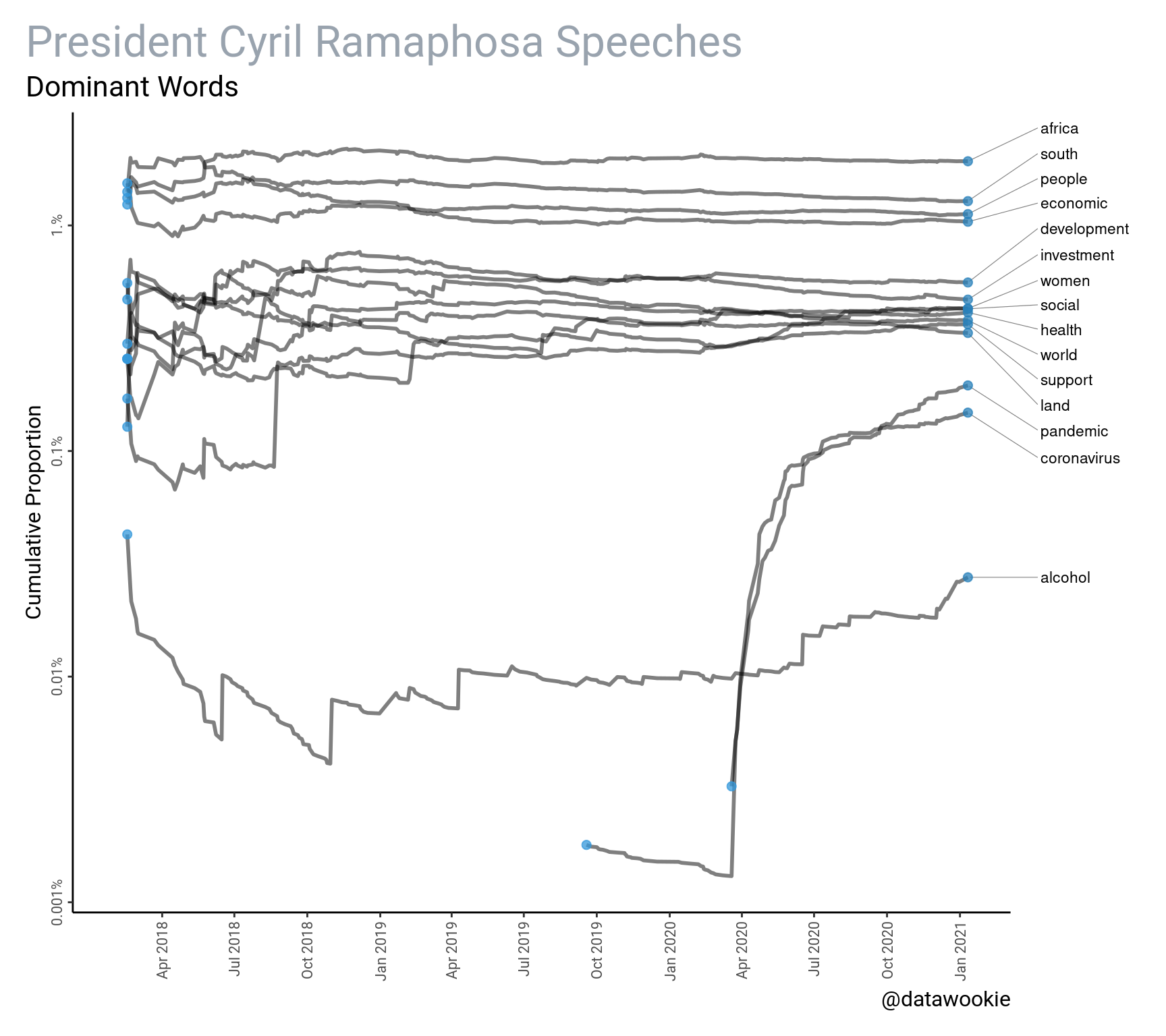
But I still like the word cloud. Let’s settle for a compromise between word cloud and time resolution.
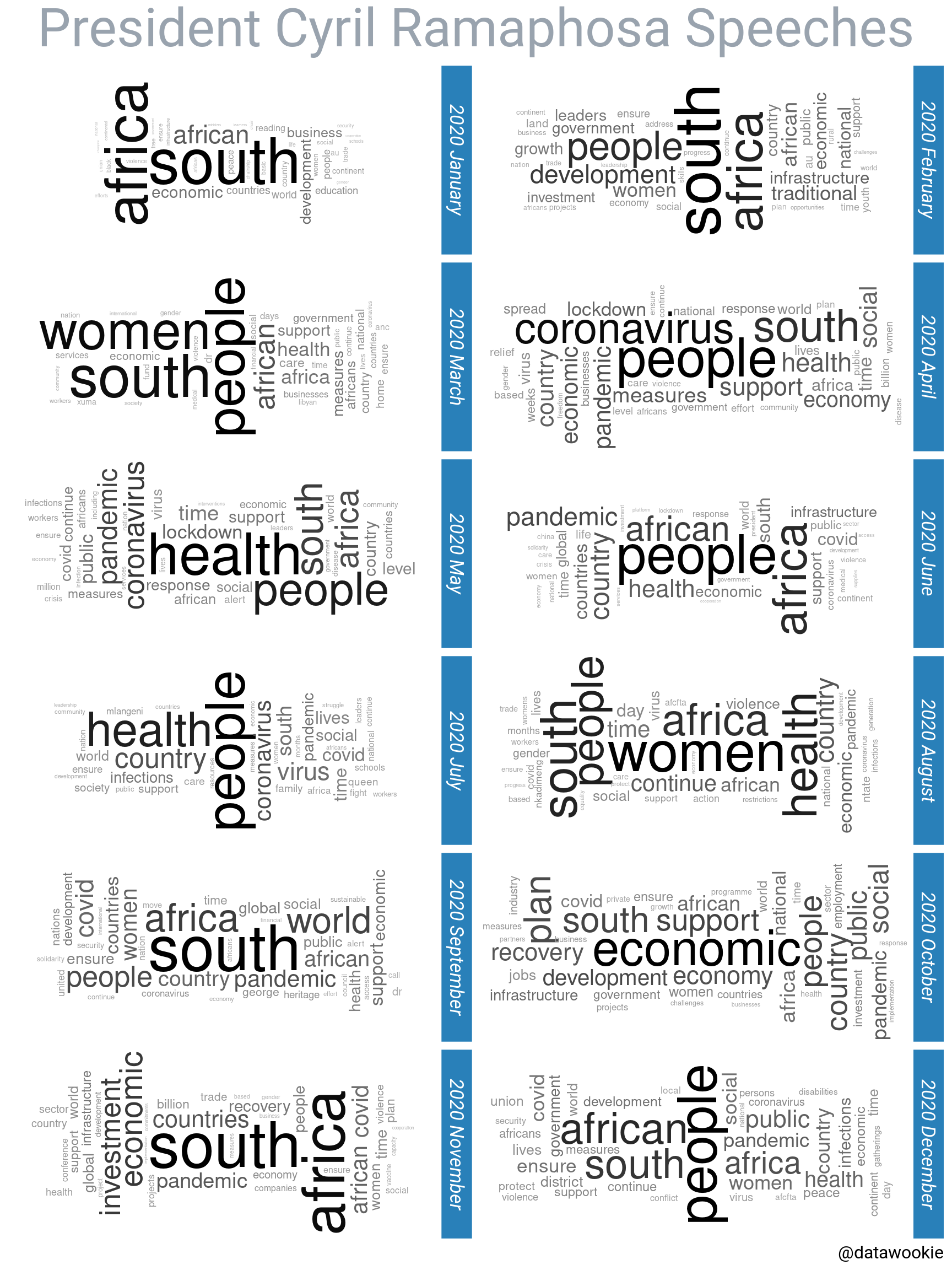
Nice! Quickly picking out a few themes:
- In August 2020 he had a lot to say about women, which makes sense since that was Women’s Month.
- In April 2020 coronavirus and people dominate, with health ascending in May 2020.
- The emphasis turned to investment and the economy in October and November 2020.
Conclusion
Looking forward to updating this data over the course of 2021 and seeing how the monologue changes.