In the last few posts we’ve looked at a few ways to set up the infrastructure for a Selenium crawler using Docker to run both the crawler and Selenium. In this post we’ll launch this setup in the cloud using AWS Elastic Container Service (ECS).
The earlier posts form an important prelude to deploying on ECS. My strategy is:
- get it running locally ✅ then
- get it running in Docker ✅ and finally
- get it running on ECS 🚀.
There are certainly better and more efficient ways to do this, but that’s not the objective here. We’re just aiming to build something minimal: it’s simple and it works.
Docker Image
We’ll need to enhance the crawler script slightly.
import sys, logging
from time import sleep
from subprocess import Popen, DEVNULL, STDOUT
from selenium import webdriver
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)7s] %(message)s',
)
HOST = "localhost"
PORT = 4444
# Check connection to host and port.
#
def check_connection():
process = Popen(
['nc', '-zv', HOST, str(PORT)],
stdout=DEVNULL,
stderr=STDOUT
)
#
if process.wait() != 0:
logging.warning(f"⛔ Unable to communicate with {HOST}:{PORT}.")
return False
else:
logging.info(f"✅ Can communicate with {HOST}:{PORT}!")
return True
RETRY = 10
for i in range(RETRY):
if check_connection():
break
logging.info("Sleeping.")
sleep(1)
else:
logging.error(f"🚨 Failed to connect to {HOST}:{PORT}!")
sys.exit(1)
SELENIUM_URL = f"http://{HOST}:{PORT}/wd/hub"
browser = webdriver.Remote(SELENIUM_URL, {'browserName': 'chrome'})
browser.get("https://www.google.com")
logging.info(f"Retrieved URL: {browser.current_url}.")
browser.close()The major changes are:
- Using the
loggingpackage for enhanced logging. - Polling port 4444 to see if Selenium is up and running (the importance of this will become apparent later on). 💡 This could easily be done in native Python, but I like the
nccommand line utility and it’s fun to run shell commands from Python. We all have different ideas about what constitutes “fun”.
The Dockerfile now also installs the netcat package.
FROM python:3.8.5-slim AS base
RUN apt-get update && apt-get install -y netcat
RUN pip3 install selenium==3.141.0
COPY google-selenium.py /
CMD python3 google-selenium.pyBuild the Docker image. I’m also tagging it with my username because I’ll be pushing it to Docker Hub.
docker build -t google-selenium -t datawookie/google-selenium .Check that it works locally. If it doesn’t work on localhost then it’s not going to work on ECS!
docker run --net=host google-selenium2021-04-24 17:08:49,114 Can communicate with localhost:4444!
Retrieved URL: https://www.google.com/.🎉 Success. Now we push the image to Docker Hub so that it’s available to ECS.
docker login
docker push datawookie/google-seleniumDefine a Task
Once we have a cluster we can create a task which specifies one or more containers which will run together.
- Click on Task Definitions (menu on left) and then press .
- Select the Fargate launch type and press .
- Choose a suitable name for the task.
- We’ll fudge the task size, specifying 1 Gb for the task memory and 0.25 vCPU for the CPU. The choice of suitable parameters for memory and CPU is not an exact science. It’ll be determined by balancing cost against performance.
- We’ll be adding two containers. Press and provide the following details:
Container 1: Selenium
- Container name:
selenium - Image:
selenium/standalone-chrome:3.141 - Port mappings:
4444
Container 2: Crawler - Container name: google-selenium - Image: The location of the crawler image, which I’ve pushed to my Docker Hub registry.
- Scroll to the bottom of the page and press .
- Click on Task Definitions again and you should see the freshly created task in the table.
- Click on the link to the task definition.
- You’ll see a list of revisions. Since we’ve just created this task there will only be a single revision. Each time we make a change to the task a new revision will be created. To review the details of the task, click on the link to the first revision.
The details of the task are captured as JSON.
The configuration file below has been abridged and edited for clarity.
{
"family": "google-selenium",
"status": "ACTIVE",
"cpu": "256",
"memory": "1024",
"networkMode": "awsvpc",
"volumes": [],
"containerDefinitions": [
{
"name": "selenium",
"image": "selenium/standalone-chrome:3.141",
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/google-selenium"
}
},
"portMappings": [
{
"hostPort": 4444,
"protocol": "tcp",
"containerPort": 4444
}
]
},
{
"name": "google-selenium",
"image": "datawookie/google-selenium",
"logConfiguration": {
"options": {
"awslogs-group": "/ecs/google-selenium",
}
}
}
],
"compatibilities": [
"EC2",
"FARGATE"
],
"requiresCompatibilities": ["FARGATE"]
}Details to note:
- The name of the task is given by the
familykey. - The operating parameters of the task are specified by the
cpuandmemorykeys. - Each container is defined by an object in the
containerDefinitionsarray. - The images, names and port mappings (where applicable) are listed for each container.
- There’s a log group associated with the task,
/ecs/google-selenium, which can be used to find logs in CloudWatch.
Networking: The task will run using the AWS Fargate serverless compute engine. The network type associated with the task is thus awsvpc, which means that containers within the task can communicate via localhost. This makes communication between containers quite simple and is not dissimilar to using the host network with Docker. The crawler will simply look for the Selenium instance at 127.0.0.1:4444 (or, equivalently, localhost:4444).
Run the Task
The moment of truth: we’re going to run the task.
- Click on Clusters (menu on left) and then the link to the cluster.
- Select the Tasks tab and press .
- Select the Fargate launch type. Choose a cluster VPC and subnet (you can just choose the first on each list).
- Whack the button.
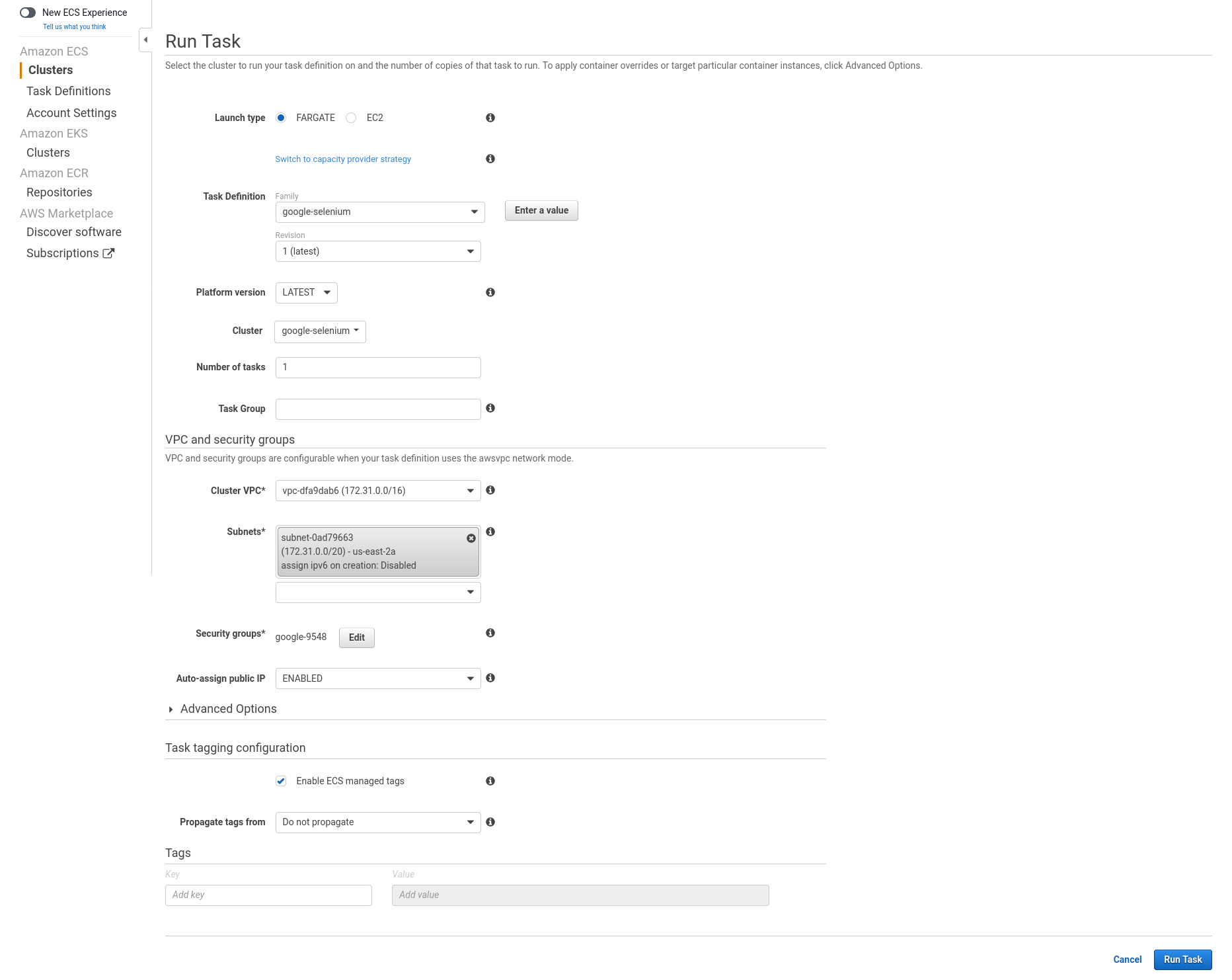
The running task will be assigned an unique task ID (like eb86fa0e2bff4aeb8e0d69bdc79eea5a). Click on the task ID link. You’ll see a table with the two containers listed, both of which will initially be in the PENDING state. Wait a moment and refresh the page. You should find that both of the containers are RUNNING. Refresh again and they should both be STOPPED. This means that the task has run and we can now inspect the logs. Click the dropdown next to each container name and follow the View logs in CloudWatch link.
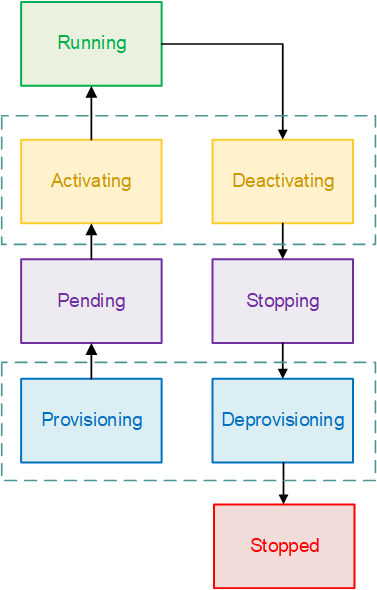
Task Lifecycle
A task will pass through a number of stages in a task lifecycle.
Task Details
On the Details tab for a task you can find the following information:
- the task definition used to launch the task;
- the role used to run the task;
- the current and desired status; and
- the private and public IP address.
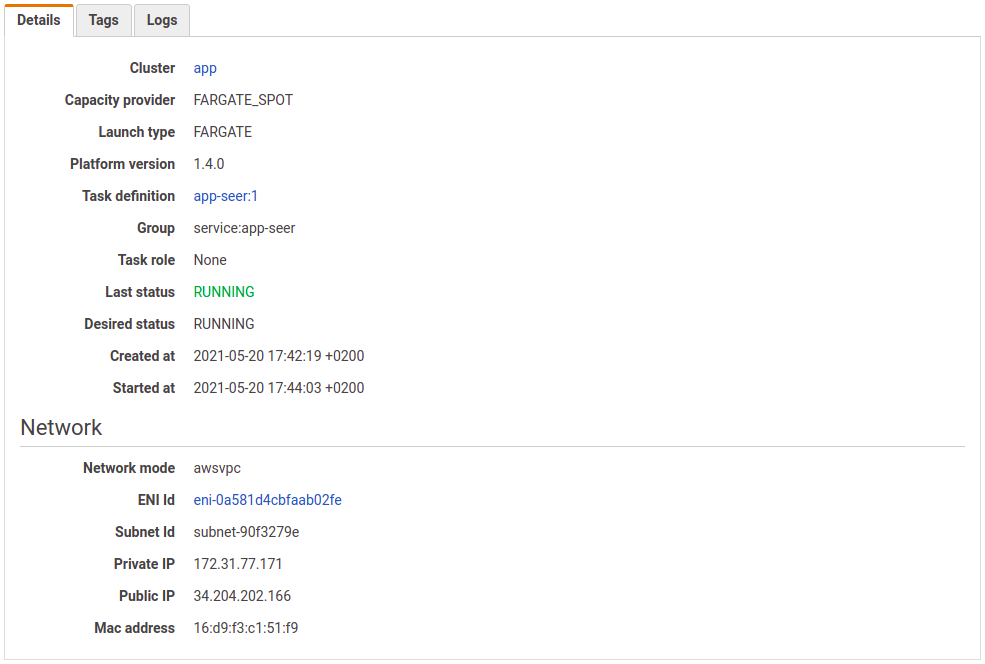
If you don’t want your task to have a public IP then you should set the Auto-assign public IP option to DISABLED when launching the task

Selenium Logs
These are the logs for the Selenium container:
2021-04-25 04:29:22,561 supervisord started with pid 8
2021-04-25 04:29:23,563 spawned: 'xvfb' with pid 10
2021-04-25 04:29:23,565 spawned: 'selenium-standalone' with pid 11
2021-04-25 04:29:24,566 success: xvfb entered RUNNING state
2021-04-25 04:29:24,566 success: selenium-standalone entered RUNNING state
04:29:25.167 Selenium server version: 3.141.59, revision: e82be7d358
04:29:25.765 Launching a standalone Selenium Server on port 4444
04:29:27.661 Initialising WebDriverServlet
04:29:28.562 Selenium Server is up and running on port 4444
04:29:34.765 Detected dialect: W3C
04:29:35.061 Started new session 04468dff0f93c1e29008b35b019799b1
Trapped SIGTERM/SIGINT/x so shutting down supervisord...
2021-04-25 04:29:39,156 received SIGTERM indicating exit request
2021-04-25 04:29:39,156 waiting for xvfb, selenium-standalone to die
2021-04-25 04:29:40,158 stopped: selenium-standalone (by SIGTERM)
2021-04-25 04:29:41,160 stopped: xvfb (by SIGTERM)
2021-04-25 04:29:41,180 Shutdown completeThe logs above have been abridged and edited for clarity.
The Selenium container was initialised at around 04:29:22 and terminated at 04:29:41. It was ready to receive requests at 04:29:28 and created a single new session at 04:29:35.
Crawler Logs
And these are the logs for the crawler:
2021-04-25 04:29:22,557 ⛔ Unable to communicate with localhost:4444.
2021-04-25 04:29:22,557 Sleeping.
2021-04-25 04:29:23,560 ⛔ Unable to communicate with localhost:4444.
2021-04-25 04:29:23,561 Sleeping.
2021-04-25 04:29:24,656 ⛔ Unable to communicate with localhost:4444.
2021-04-25 04:29:24,656 Sleeping.
2021-04-25 04:29:25,756 ⛔ Unable to communicate with localhost:4444.
2021-04-25 04:29:25,756 Sleeping.
2021-04-25 04:29:26,761 ⛔ Unable to communicate with localhost:4444.
2021-04-25 04:29:26,761 Sleeping.
2021-04-25 04:29:27,766 ⛔ Unable to communicate with localhost:4444.
2021-04-25 04:29:27,767 Sleeping.
2021-04-25 04:29:28,860 ✅ Can communicate with localhost:4444!
2021-04-25 04:29:38,258 Retrieved URL: https://www.google.com/.The crawler container was initialised at 04:29:22. This was before the Selenium container was ready to receive requests, so the first few attempts to communicate with Selenium were unsuccessful. However, by 04:29:28 the Selenium container was ready to receive requests (see Selenium logs above) and the crawler was able to establish communication. It was at this point that the crawler triggered the creation of a new Selenium session and retrieved the content of https://www.google.com/. The crawler then exited, which in turn caused the Selenium container to terminate.
Conclusion
Waiting for the Selenium service is paramount. If we didn’t wait then the crawler would fail and terminate before Selenium was ready to accept requests. In later posts we’ll see how to create explicit dependencies between containers.
There you have it, a minimal setup to run your containers in a serverless environment on AWS Elastic Container Service. Although I’ve illustrated the principles with a simple Selenium crawler, the same approach can be used for many other container configurations. 🚀