At Fathom Data we tend to do quite a lot of web scraping. At the moment I’m working on a small project which requires assembling a large selection of RSS feeds. Aggregator sites (like Feedspot and Feedly) have extensive, carefully curated lists of RSS feeds. As we’ll see below, the underlying lists are not entirely trivial to access.
In principle you could gather those feeds by hand. But we’re targeting a large number of feeds. This would be a gruelling task to do manually and is really ripe for automation. In this process I’ll describe a simple approach to harvesting RSS feeds using Python.
Case Study
Just to appreciate what’s involved, let’s take a look at the process of gathering those feed URLs manually. Start off by going to the Top 100 Education RSS Feeds list on Feedspot.
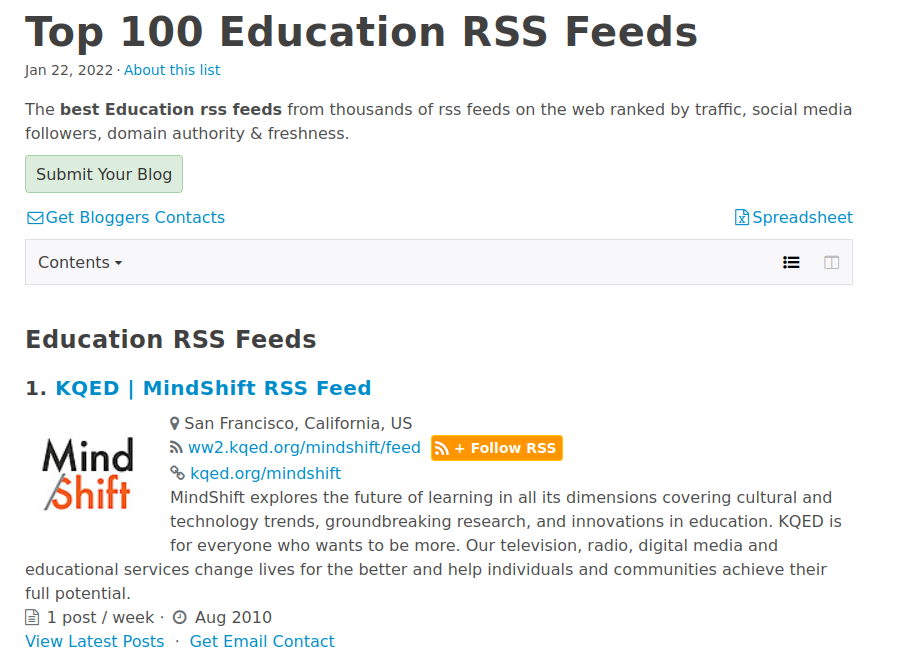
If we were interested in the “KQED | MindShift” feed then we’d click on the orange “Follow RSS”.
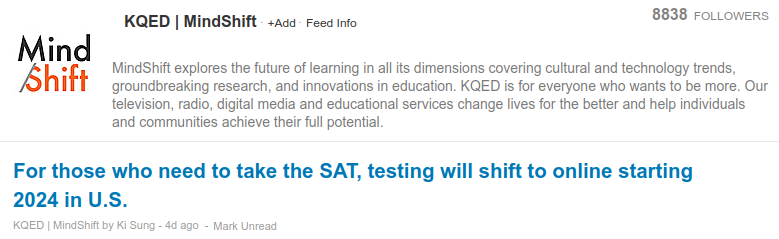
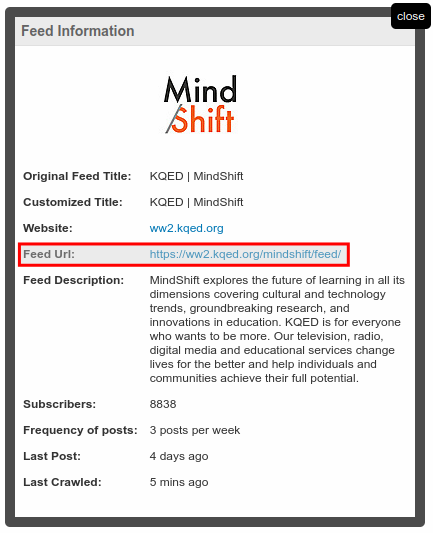
We haven’t actually gone to the selected feed. We’re simply on the page for that feed on Feedspot. We’re making progress, but we’re not there yet. To get the feed URL you’d need to press the “Feed Info” link, which would pop up a modal dialog. The URL that we’re looking for is https://ww2.kqed.org/mindshift/feed/. That’s the actual information that we’re after. But we had to jump through a number of hoops to get at it. If we were gathering a few hundred URLs, then this would translate into a lot of boring, repetitive work.
Automation
This is the sort of task that’s literally begging to be automated.
What tools do you need to do the job? We built the crawler with Python and the following packages:
requests— for retrieving content from URLs;backoff— for retrying with exponential backoff;bs4— for parsing retrieved HTML;re— for post-processing content; andlogging— for keeping track of what’s happening and when.
The only mildly tricky component of the whole process was retrieving the data from the modal dialog, which is rendered using JavaScript.
Putting the crawler together took an hour or so. But now we can run it over a range of different topics and gather the related RSS URLs.
Samples
Here are some samples of the retrieved data. First a selection of the RSS feeds relating to “education”:
"KQED | MindShift",https://ww2.kqed.org/mindshift/feed/,
"TeachThought",https://www.teachthought.com/feed/,
"eLearning Industry | Online Education Blog",http://feeds.feedburner.com/elearningindustry,
"WeAreTeachers | Educators Blog",https://www.weareteachers.com/feed,
"Khan Academy Blog",https://blog.khanacademy.org/feed/,
"U.S. Department Of Education",https://blog.ed.gov/feed/,
"HuffPost » Education",https://www.huffpost.com/section/education/feed,
"EdSurge",https://www.edsurge.com/articles_rss,
"BusyTeacher | Free Printable Worksheets ",https://busyteacher.org/rss.xml,
"Faculty Focus",https://www.facultyfocus.com/feed/,And here are some RSS feeds relevant to “market research”:
"Nielsen | Latest Consumer Insights and Market Research Trends",http://feeds.feedburner.com/NielsenWire,
"Market Research Blog",http://blog.marketresearch.com/rss.xml,
"GreenBook | Charting the Future of Market Research",https://www.greenbook.org/mr/feed/,
"Global Market Insights | Market Research Blog ",https://www.gminsights.com/feed/blogs.xml,
"Verified Market Research (VMR)",https://www.verifiedmarketresearch.com/feed/,
"Fortune Business Insights",https://rss2.feedspot.com/https://www.fortunebusinessinsights.com/blogs,
" Ken Research Blog",https://www.kenresearch.com/blog/feed/,
"BIS Research",https://blog.bisresearch.com/rss.xml,
"Open ends - A publication about market research by Askia",https://blog.askia.com/feed/,
"Fact.MR",https://blog.factmr.com/feed,