Marshmallow can readily handle nested schemas. But sometimes it’s preferable to flatten that schema for loading and/or dumping the data. The fields.Pluck() class makes this possible.
The Tables
Suppose that you have a collection of tables for capturing address data. There are various ways that you could do this, one of which might involve breaking the address down into components:
- country
- city
- postal code (effectively a small neighbourhood) and
- street address.
The tables look like this:
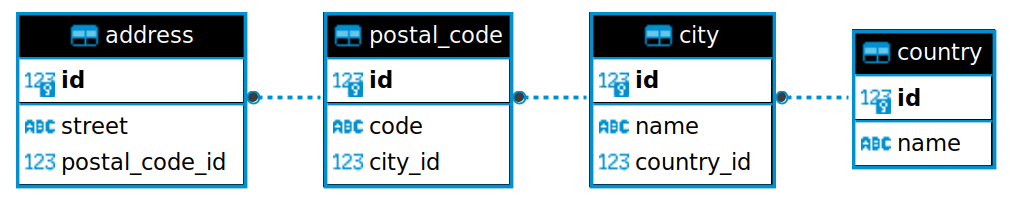
The corresponding SQLAlchemy classes can be found in a database.py module. The tables are linked via foreign key relationships, which effectively nest country objects within city objects, city objects with postal_code objects and postal_code objects within address objects. This design aims to eliminate (or at least minimise) duplication of data.
The Objects
Let’s insert some objects into that schema.
downing_street
westminster
london
englandAddress(id=1, street="10 Downing Street", postal_code_id=1)
PostalCode(id=1, code="SW1A 2AA", city_id=1)
City(id=1, name="London", country_id=1)
Country(id=1, name="England")Because of the schema design we can use object attributes to access the components of an address. Starting with the Address object we can extract its postal code.
downing_street.postal_codePostalCode(id=1, code="SW1A 2AA", city_id=1)From the postal code we get the city.
downing_street.postal_code.cityCity(id=1, name="London", country_id=1)And from the city we get the country.
downing_street.postal_code.city.countryCountry(id=1, name="England")Despite the nested relationship in the database, it would be convenient to work with these data as a flattened structure, where all of the address components are at the same level (not nested!). Why? I’m going to access these data via an API and want to be able to easily load and dump address data without having to deal with nesting.
For ease of reference there are also properties on the Address object which give direct access to city and country.
downing_street.cityCity(id=1, name="London", country_id=1)downing_street.countryCountry(id=1, name="England")My focus is going to be on creating Marshmallow schema classes to load (deserialise) and dump (serialise) these data. Ideally I’d like to load and dump these data using a JSON structure like this:
{
"street": "10 Downing Street",
"postal_code": "SW1A 2AA",
"city": "London",
"country": "England"
} ← ⭐⭐⭐ This is what I'm aiming for!Nested Schemas
My initial approach would be to create a series of nested schemas using fields.Nested().
from marshmallow import Schema, fields
class CountrySchema(Schema):
name = fields.String()
class CitySchema(Schema):
name = fields.String()
country = fields.Nested(CountrySchema)
class PostalCodeSchema(Schema):
code = fields.String()
city = fields.Nested(CitySchema)
class AddressSchema(Schema):
street = fields.String()
postal_code = fields.Nested(PostalCodeSchema)Let’s try that out for dumping an Address object.
AddressSchema().dumps(downing_street, indent=2){
"street": "10 Downing Street",
"postal_code": {
"code": "SW1A 2AA",
"city": {
"name": "London",
"country": {
"name": "England"
}
}
}
} ← ☹️ This is not what I want!It’s far from the ideal flat JSON layout I’d like to achieve. It’d be rather inconvenient to use this layout for dumping or loading data.
Flattened for Dump
Instead of nesting the schemas via fields.Nested(), use the fields.Pluck() class to access fields in subordinate schemas directly.
from marshmallow import Schema, fields
class CountrySchema(Schema):
name = fields.String()
class CitySchema(Schema):
name = fields.String()
class PostalCodeSchema(Schema):
code = fields.String()
class AddressSchema(Schema):
street = fields.String()
postal_code = fields.Pluck(PostalCodeSchema, "code")
city = fields.Pluck(CitySchema, "name")
country = fields.Pluck(CountrySchema, "name")This dumps a perfectly flat JSON object. Just what I wanted.
AddressSchema().dumps(downing_street, indent=2){
"postal_code": "SW1A 2AA",
"country": "England",
"street": "10 Downing Street",
"city": "London"
} ← 🙂️ This is more like it!💡 You can pluck multiple values by passing many=True to fields.Pluck().
What about loading? Those schema classes actually work fine for dumping and loading a flattened structure.
import json
# Dump to a dictionary.
dumped = AddressSchema().dump(downing_street)
# Load and pretty print.
json.dumps(AddressSchema().load(dumped), indent=2){
"street": "10 Downing Street",
"city": {
"name": "London"
},
"country": {
"name": "England"
},
"postal_code": {
"code": "SW1A 2AA"
}
} ← 😠 Not ideal!But (bummer!) the loaded result is nested! Not a disaster, but also not terribly convenient. We’re halfway there though.
Flattened for Dump and Load
This is the final solution that I came up with. It handles loading and dumping of flattened data but also plays nicely with the underlying SQLAlchemy classes. There are separate attributes for loading and dumping data from the subordinate objects. The @post_dump decorator is used to strip the _dump suffix off the dumped field names.
import re
from marshmallow import Schema, fields, post_dump
class CountrySchema(Schema):
name = fields.String()
class CitySchema(Schema):
name = fields.String()
class PostalCodeSchema(Schema):
code = fields.String()
class AddressSchema(Schema):
street = fields.String()
# Dump
postal_code_dump = fields.Pluck(
PostalCodeSchema, "code", dump_only=True, attribute="postal_code"
)
city_dump = fields.Pluck(
CitySchema, "name", dump_only=True, attribute="city"
)
country_dump = fields.Pluck(
CountrySchema, "name", dump_only=True, attribute="country"
)
# Load
postal_code = fields.String(load_only=True)
city = fields.String(load_only=True)
country = fields.String(load_only=True)
@post_dump
def remove_dump_suffix(self, data, **kwargs):
# Strip "_dump" suffix off field names.
keys = [re.sub("_dump$", "", key) for key in data.keys()]
return dict(zip(keys, list(data.values())))Loading works precisely as before, but now the dumped data are flat too. 💡 Without the remove_dump_suffix() method the dumped field names would all have a _dump suffix.
dumped = AddressSchema().dump(downing_street)
json.dumps(AddressSchema().load(dumped), indent=2){
"street": "10 Downing Street",
"country": "England",
"postal_code": "SW1A 2AA",
"city": "London"
} ← 🤩 This is precisely what I want.Although the underlying data representation is nested, both serialisation and deserialisation work with a flattened structure. I arrived at this approach via trial and error. There are probably better ways to do this. If so, I’d love to know.