
In the previous post we completed the implementation of multiple site versions. There’s now more than one version of each of the content pages. From a developer and user perspective this is ideal: we have granular documentation for each version of our fictitious site. However, for SEO purposes this is not ideal.
Multiple versions of the same content are not good for SEO because it can lead to lower rankings for the following reasons:
- inbound link juice diluted;
- search engine confusion (which version to index and rank?); and
- consuming crawl budget (search engines will only crawl a limited number of pages from a site and you don’t want to waste that budget!).
From an analytics perspective it’s also not great because your statistics get spread across multiple pages.
🚀 TL;DR
Show me the code. Look at the 14-canonical branch. This site is deployed here.
What are Canonical Links?
A canonical link is a way of telling search engines which version of a page with similar or duplicate content is the official or preferred version. Users generally want to see the most recent version of the documentation, so that’s where the canonical link should normally point.
Our site has multiple versions of content pages. For example, the “What is Gatsby?” page can be found at the following paths:
/0.1/what-is-gatsby//0.2/what-is-gatsby//0.3/what-is-gatsby//1.0/what-is-gatsby//1.1/what-is-gatsby/and/1.2/what-is-gatsby/.
Of these, the last (the most recent version) is the most relevant, so that should be the target of the canonical link.
A canonical link consists of a <link> tag in the <head> of the HTML document. We’ll see some examples shortly.
💡 The href attribute for a canonical <link> tag will always be an absolute URL.
Why are Canonical Links Important?
A canonical link will remove the ambiguity around which page contains the most relevant (or “canonical”) version of the content. They help for SEO. And they improve UX.
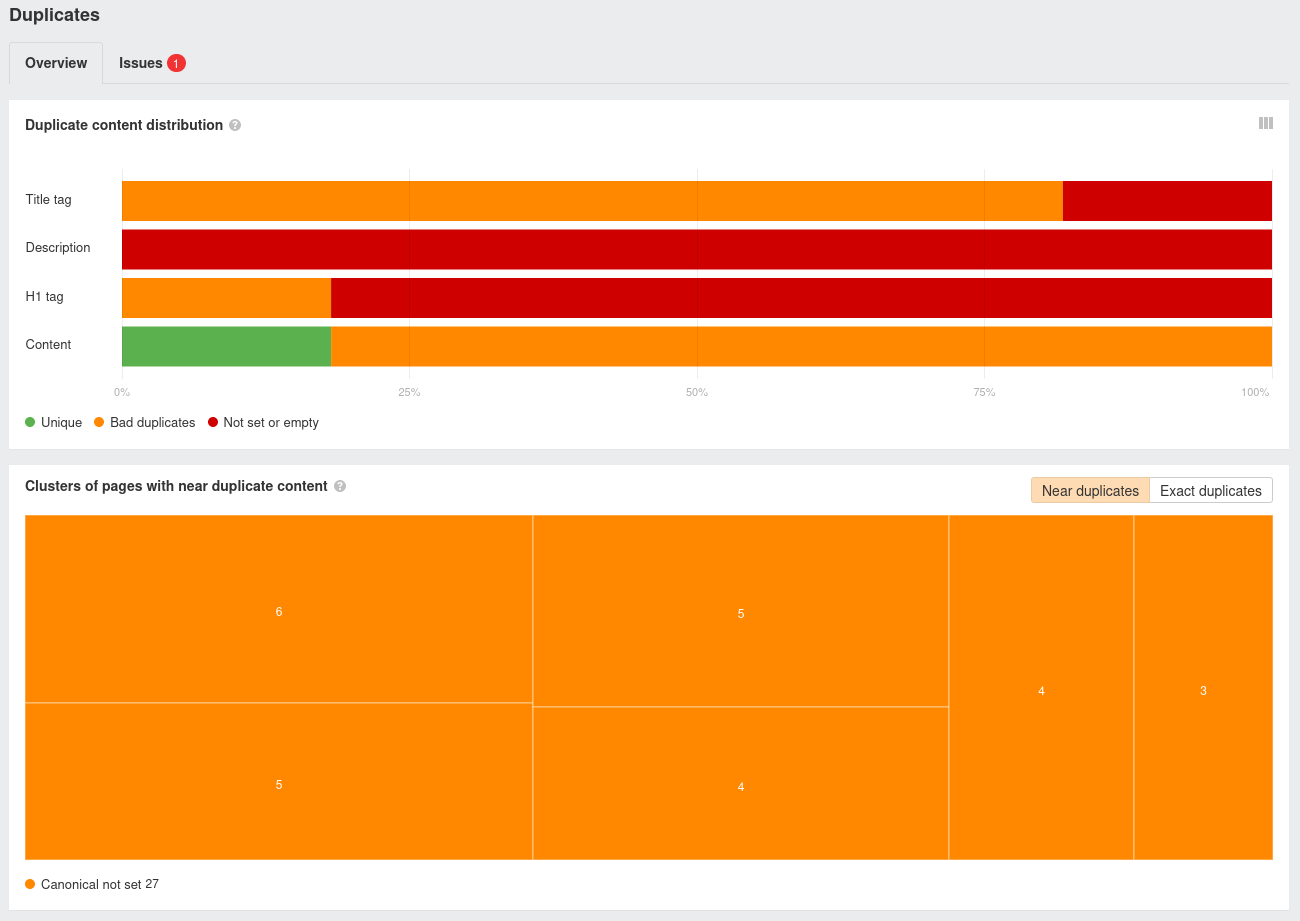
Below is a snapshot of the ahrefs duplicates dashboard for the site before introducing the canonical links. There’s a lot of orange and red in there: things that need to be fixed!
Constructing the Canonical URL
The target of the canonical link needs to be an absolute URL. We’ll use the domain specified as siteMetadata.siteUrl in gatsby-config.js to construct the absolute URL.
To make siteMetadata.siteUrl we’ll add the following to the GraphQL queries in src/pages/home.js (for the landing page) and src/templates/article.js (for the content pages):
site {
siteMetadata {
siteUrl
}
}
Canonical Tag in Landing Page
To add a canonical link to the landing page we’ll export a Head component from src/pages/home.js. The component uses the useSiteLatestVersion hook to get the latest version for the site.
The resulting canonical link looks like this:
<link rel="canonical" href="https://www.whimsyweb.dev/1.2/" data-gatsby-head="true">
Canonical Tag in Content Pages
To add a canonical link to the content pages we’ll export a Head component from src/templates/article.js. The site latest version is passed to the template via the context argument to createPage(). Within the template it’s accessible via pageContext.
For the “What is Gatsby?” page this is what the canonical link would look like:
<link rel="canonical" href="https://www.whimsyweb.dev/1.2/what-is-gatsby/">
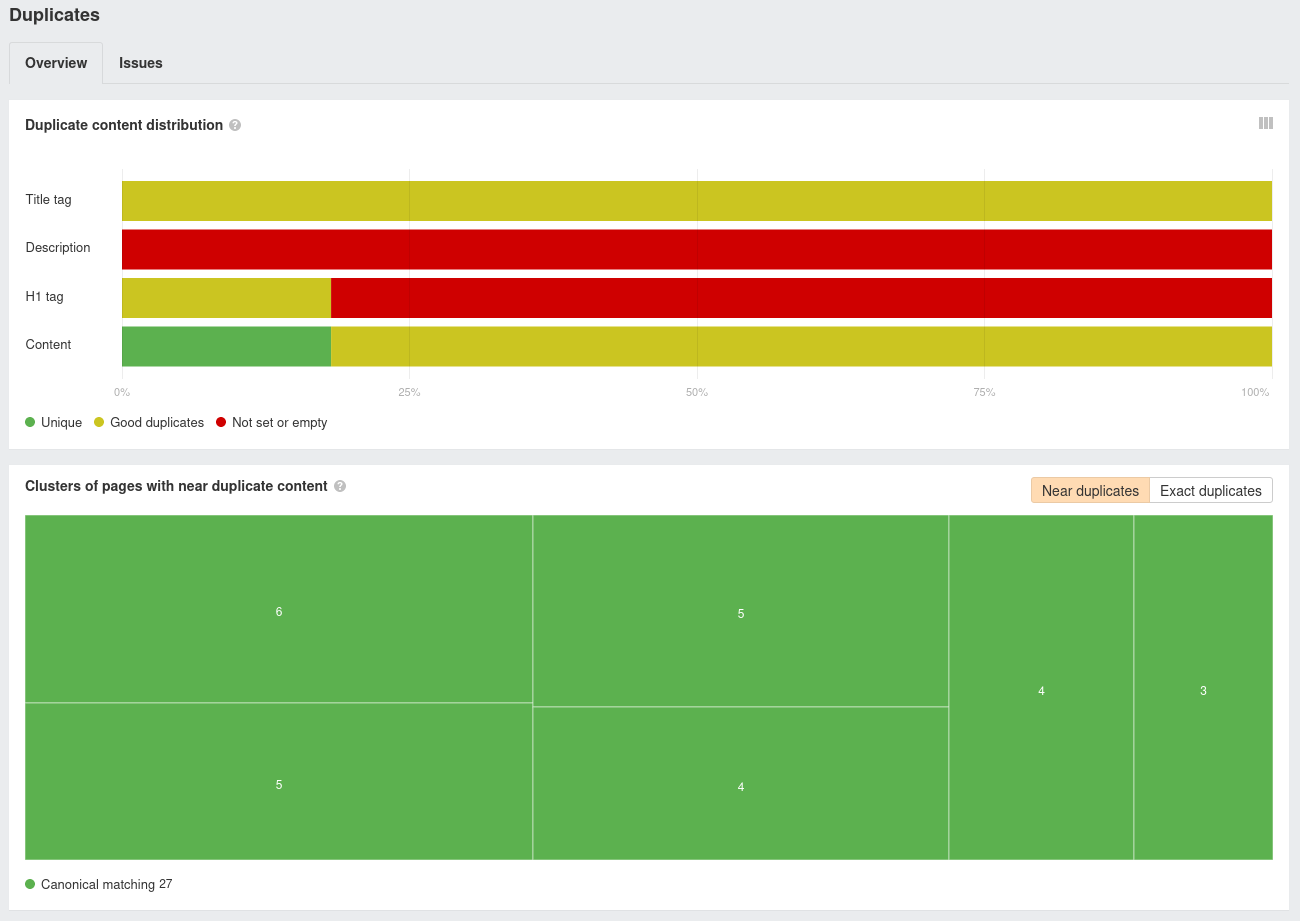
And here’s the ahrefs duplicates dashboard after introducing the canonical links. There’s some red in there, but there’s also a lot of green now. Still work to be done, but a massive improvement already.
When Not to Index
Now that we have canonical links, any search engine crawling the site will be able to figure out which is the definitive (or canonical) version of each piece of content. But this doesn’t necessarily stop the crawler from indexing the non-canonical pages. We can add some extra insurance by inserting a noindex robots tag into those pages too.
<meta name="robots" content="noindex">
This simply tells search engine crawlers not to index the page. It’s really just a suggestion. It’s not going to stop them from indexing the page. Let’s think of it as a strong hint.
We’ll conditionally insert this tag into the <head> of all pages by making small changes to src/pages/home.js and src/templates/article.js.
Number of Pages Indexed
I submitted the old and new versions of the site for indexing by Bing. This is what Bing Webmaster tools told me about the old version of the site:

It indexed 36 pages, which means that it consumed all versions of the pages. However, after adding the canonical tags this is what it told me:

The number of indexed pages has dropped to only 8, meaning that only the canonical version of each page has been considered.
Conclusion
Adding canonical links to your site is relatively quick and easy. If you have multiple pages with similar content then the canonical links will undoubtedly improve your SEO performance.