In my previous post I used the tm package to do some simple text mining on the Complete Works of William Shakespeare. Today I am taking some of those results and using them to generate word clusters.
Preparing the Data
I will start with the Term Document Matrix (TDM) consisting of 71 words commonly used by Shakespeare.
inspect(TDM.common[1:10,1:10])
A term-document matrix (10 terms, 10 documents)
Non-/sparse entries: 94/6
Sparsity : 6%
Maximal term length: 6
Weighting : term frequency (tf)
Docs
Terms 1 2 3 4 5 6 7 8 9 10
act 1 4 7 9 6 3 2 14 1 0
art 53 0 9 3 5 3 2 17 0 6
away 18 5 8 4 2 10 5 13 1 7
call 17 1 4 2 2 1 6 17 3 7
can 44 8 12 5 10 6 10 24 1 5
come 19 9 16 17 12 15 14 89 9 15
day 43 2 2 4 1 5 3 17 2 3
enter 0 7 12 11 10 10 14 87 4 6
exeunt 0 3 8 8 5 4 7 49 1 4
exit 0 6 8 5 6 5 3 31 3 2
This matrix is first converted from a sparse data format into a conventional matrix.
TDM.dense <- as.matrix(TDM.common)
dim(TDM.dense)
[1] 71 182
Next the TDM is normalised so that the rows sum to unity. Each entry in the normalised TDM then represents the number of times that a word occurs in a particular document relative to the number of occurrences across all of the documents.
TDM.scaled <- TDM.dense / rowSums(TDM.dense)
Clustering
We will be using a hierarchical clustering technique which operates on a dissimilarity matrix. We will use the Euclidean distance between each of the rows in the TDM, where each row is treated as a vector in a space of 182 dimensions.
TDM.dist = dist(TDM.scaled)
Finally we perform agglomerative clustering using agnes() from the cluster package.
library(cluster)
hclusters hclusters
Call: agnes(x = TDM.dist, method = "complete")
Agglomerative coefficient: 0.6256247
Order of objects:
[1] act great way away hand stand life can hath yet
[11] look see leav let shall make take thus made till
[21] come well will good ill like now give upon know
[31] may must man much think hear speak never one say
[41] tell enter exeunt scene exit tis mean fear men keep
[51] word name lord call two old sir first art thee
[61] thou thi day live heart mine time part true eye
[71] love
Height (summary):
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.02495 0.04509 0.05722 0.06050 0.06897 0.14260
Available components:
[1] "order" "height" "ac" "merge" "diss" "call"
[7] "method" "order.lab"
Plotting a Dendrogram
Let’s have a look at the results of our labours.
plot(hclusters, which.plots = 2, main = "", sub = "", xlab = "")
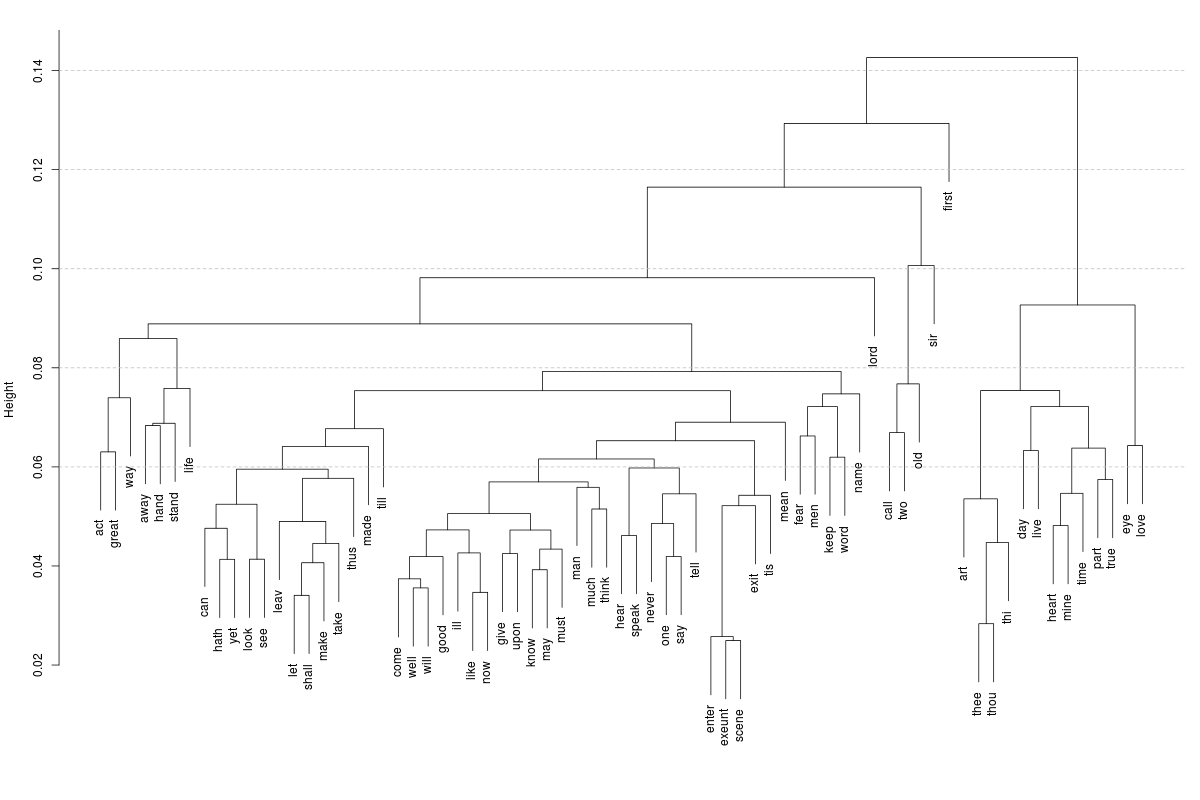
This dendrogram reflects the tree-like structure of the word clusters. We can see that the words “enter”, “exeunt” and “scene” are clustered together, which makes sense since they are related to stage directions. Also “thee” and “thou” have similar usage. In the previous analysis we found that the occurrences of “love” and “eye” were highly correlated and consequently we find them clustered here too.
This is rather cool. No doubt a similar analysis applied to contemporary literature would yield extremely different results. Anybody keen on clustering the Complete Works of Terry Pratchett?