A few days ago I posted about Filtering Data with L2 Regularisation. Today I am going to explore the other filtering technique described in the paper by Tung-Lam Dao.
This is similar to the filter discussed in my previous post, but uses a slightly different objective function:
$$ \frac{1}{2} \sum_{t=1}^n (y_t - x_t)^2 + \lambda \sum_{t=2}^{n-1} |x_{t-1} - 2 x_t + x_{t+1}| $$
where the regularisation term now employs the L1 “taxi cab” metric (rather than the L2 Euclidean metric).
Implementation and Test Data
The filter function is a slight adaption of the one I used previously.
l1filter.optim <- function (x, lambda = 0.0) {
objective <- function(y, lambda) {
n <- length(x)
P1 = 0.5 * sum((y - x)**2)
#
P2 = 0
for (i in 2:(n-1)) {
P2 = P2 + abs(y[i-1] - 2 * y[i] + y[i+1])
}
#
P1 + lambda * P2
}
#
fit = optim(x, objective, lambda = lambda, method = "CG", control = list(maxit = 100000, type = 3))
if (fit$convergence != 0) {
warning(sprintf("Optimisation failed to converge! (lambda = %f)", lambda))
print(fit)
}
return(fit$par)
}
I changed optimisation method from BFGS to conjugate gradient (CG) because, upon testing, the latter required fewer evaluations of both the objective function and its gradient. I also played around with the various update types used with conjugate gradient and found that Beale–Sorenson provided better performance than either Fletcher–Reeves or Polak–Ribiere.
A noisy sawtooth waveform serves well to demonstrate this filter.
y <- rep(0:10, 5)
#
# Add in some noise
#
y <- y + rnorm(length(y))
We systematically apply the L1 filter with a range of regularisation parameters extending from 1 to 10000 in multiples of 10.
lambda = c(0, 10**(0:4))
Y1 <- lapply(lambda, function(L) {l1filter.optim(y, L)})
#
Y1 = do.call(cbind, Y1)
#
Y1 = as.data.frame(cbind(1:length(y), y, Y1))
#
names(Y1) <- c("x", "raw", sprintf("%g", lambda))
head(Y1)
x raw lambda value
1 1 1.98040 0 1.98040
2 2 0.63278 0 0.63278
3 3 0.95587 0 0.95587
4 4 3.56972 0 3.56972
5 5 3.86495 0 3.86495
6 6 7.40162 0 7.40162
And then use the L2 filter with the same regularisation parameters for comparison.
Y2 <- lapply(lambda, function(L) {l2filter.matrix(y, L)})
#
Y2 = do.call(cbind, Y2)
#
Y2 = as.data.frame(cbind(1:length(y), Y2))
#
names(Y2) <- c("x", sprintf("%g", lambda))
head(Y2)
x lambda value
1 1 0 1.98040
2 2 0 0.63278
3 3 0 0.95587
4 4 0 3.56972
5 5 0 3.86495
6 6 0 7.40162
In the plot below the two filtered signals are compared to the raw data (points), with the L1 filtered data plotted as a solid line and the L2 filtered data as a dashed line.
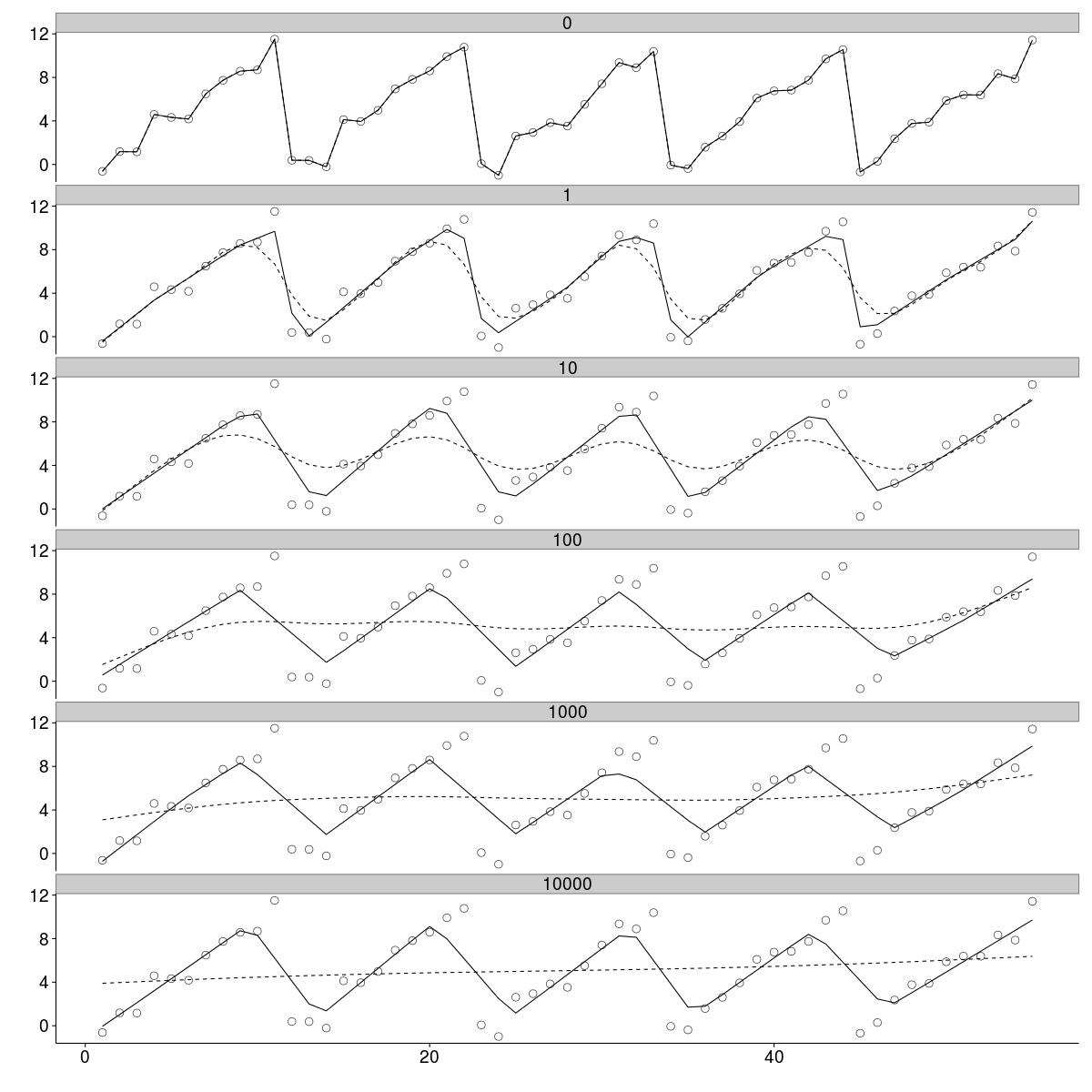
Without regularisation (\(\lambda = 0\)) the filtered signals are identical to the raw data. As the strength of regularisation increases, the difference between the L1 and L2 filtered data emerges. While the L2 filter tends to produce a smooth curve, the L1 filter attempts to approximate the raw data by a series of straight line segments. The degree of regularisation determines the number of segments (or equivalently, the number of breaks between segments). With strong regularisation (bottom panel), the L2 filter has completely smoothed out any variation in the raw data, while the L1 filter retains a good approximation to the original (noise free) signal.
Comparing L1 and L2 Regularisation
The fundamental difference between L1 and L2 regularisation is that the former is linear while the latter is not.
L2 regularisation attempts to minimise the curvature at all points by applying a penalty which scales as the square of the curvature at each point. Points with high curvature are thus heavily penalised. For example, if one compares a set of five points, each of which has a curvature of 1, to another set, where four have a curvature of 0 and one has a curvature of 5, then the latter incurs a much higher regularisation penalty: \(25 \lambda\) versus only \(5 \lambda\).
On the other hand, L1 regularisation applies a penalty which is linear in curvature. In the previous example, the two sets would incur exactly the same penalty. The consequence is that L1 regularisation tends to produce many points with 0 curvature and a smaller number of points with non-zero curvature. Each series of points with 0 curvature forms a linear (straight line) segment, which is separated from the next at a break point. At the break point the curvature is non-zero and one linear segment is joined to another with different slope.
Comparing L1 and L2 Regularisation
I anticipate that I will find a place for both of these techniques in my analyses. Certainly in situations where I suspect that the underlying data are linear, I will filter with strong L1 regularisation. In the absence of any premonitions about the underlying data, I suspect that moderate L2 regularisation would provide the most intuitive results.