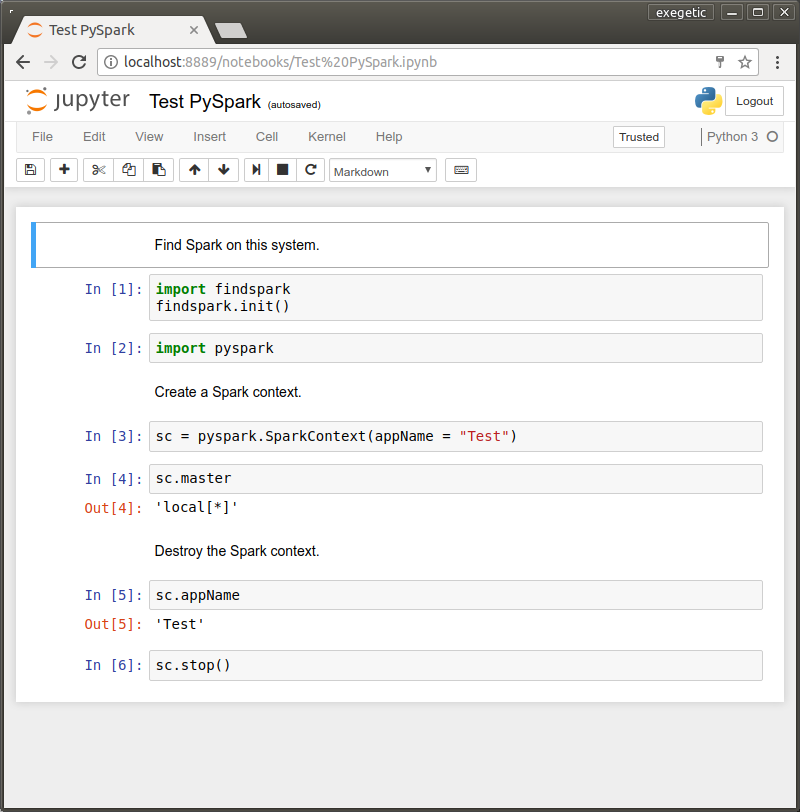
It’d be great to interact with PySpark from a Jupyter Notebook. This post describes how to get that set up. It assumes that you’ve installed Spark like this.
- Install the
findsparkpackage.pip3 install findspark - Make sure that the
SPARK_HOMEenvironment variable is defined - Launch a Jupyter Notebook.
jupyter notebook - Import the
findsparkpackage and then usefindspark.init()to locate the Spark process and then load thepysparkmodule. See below for a simple example.